Go语言基础知识学习笔记
环境准备
下载安装Golang:https://golang.google.cn/dl/
因为国外下载速度较慢,我们需要配置国内代理
# 开启包管理工具
go env -w GO111MODULE=on
# 设置代理
go env -w GOPROXY=https://goproxy.cn,direct
# 设置不走 proxy 的私有仓库,多个用逗号相隔(可选)
go env -w GOPRIVATE=*.corp.example.com
Let’s go!
安装Goland,在全局配置中配置GoProxy

创建项目,选第一个,默认是go mod管理依赖包

创建main.go,编写代码:
package mainimport ("fmt"
)func main() {fmt.Println("Let's go!")
}
编译/运行:
go run main.go
基础知识
走进Golang
Golang是静态语言,但给人的感觉是动态语言,既提高了开发效率,又保证了系统的性能,其位置可以简单理解为处于Python和C之间,难度一般,有Java基础或Python基础可以很快上手
Golang的语法与Python很相似,同时吸收了C语言和JavaScript的语法,并对Java的一些思想做了借鉴,例如接口,但是在Golang中没有对象这个概念,取而代之的是结构体(Struct)
如果非要给学习go语言一个理由的话,理由如下:
- Google开源,技术大咖为GoLang做输出
- 编译型语言,开发效率比C高,速度比Python快,比Java略低
- 部署十分简单,大大减少了成本
- 天生支持并发
Golang的设计有些特点:
-
如果只声明不使用则会编译不通过,除非命名为
_ -
如果项目依赖必须引用则需要取名为
_, -
大括号必须是右上角-左下角格式,不能是上下格式,否则编译不通过,例如
-
Golang不论什么数据类型的传递都是值传递,如果想引用传递则需要使用指针
-
Golang简化了指针的使用,例如user是一个结构体指针,
*(user).name与user.name是一个意思 -
Golang中只有for循环,没有while循环,可以用for循环实现while的效果
-
一个项目必须有一个main包,即package main,一个main包有且只有一个main函数,这个函数是项目的入口
综合看来,Golang的难度一般,同时大厂需求较大,未来三年将的地位将发生大变化,提前入局是比较好的选择
变量与常量
声明变量
在Golang中,变量的声明使用var关键字,变量类型写在后面,变量声明后不需要赋值,Golang会默认赋值
var a int
a = 10
我们通常使用:=进行变量声明和赋值,上述代码可以合并为
a := 10
一个小案例
func main() {// 同时声明两个变量var b, c int = 1, 2// 声明一个变量并初始化var a = "RUNOOB"// 没有初始化就为零值var b int
}
一些声明的样例:
var a *int
var a []int
var a map[string] int
var a chan int
var a func(string) int
var a error // error 是接口
匿名变量
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示,例如:
func foo() (int, string) {return 10, "Q1mi"
}
func main() {x, _ := foo()_, y := foo()fmt.Println("x=", x)fmt.Println("y=", y)
}
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。 (在Lua等编程语言里,匿名变量也被叫做哑元变量。)
注意事项:
- 函数外的每个语句都必须以关键字开始(var、const、func等)
:=不能使用在函数外。_多用于占位,表示忽略值。
声明常量
Golang使用const关键字声明常量,可以一次声明一个,也可以一次声明多个
const LENGTH int = 10
const WIDTH int = 5const (Unknown = 0Female = 1Male = 2
)
iota是一种特殊常量,可以认为是一个可以被编译器修改的常量,可以是常量操作,也可以是表达式
import "fmt"func main() {const (a = iota //0b //1c //2d = "ha" //独立值,iota += 1e //"ha" iota += 1f = 100 //iota +=1g //100 iota +=1h = iota //7,恢复计数i //8)fmt.Println(a,b,c,d,e,f,g,h,i)const (i=1<<iota //1j=3<<iota //6k //12l //24)fmt.Println("i=",i)fmt.Println("j=",j)fmt.Println("k=",k)fmt.Println("l=",l)
}
基本数据类型
数据类型介绍
关于各类型最大值可以通过math.MaxFloat32获取
- 布尔型:true、false
- 整数类型:uint8、uint16、uint32、uint64、int8、int16、int32、int64
- 浮点型:float32、float64
- 复数类型:complex64、complex128
- 字符串:双引号包裹,采用UTF-8编码,一个
汉字需要3个字节编码 - Go 语言的字符型有以下两种:
uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。rune类型,代表一个UTF-8字符。- 当需要处理中文、日文或者其他复合字符时,则需要用到
rune类型。rune类型实际是一个int32。
字符串操作与Python类似,但是求长度的时候需要注意编码,在utf-8编码当中,如果直接求len则会显示编码长度,我们需要使用rune数组
str := "hello 帅帅龙"
fmt.Println(len(str)) //得到15fmt.Println(len([]rune(str))) //得到9
类型转换
通常情况下
func sqrtDemo() {var a, b = 3, 4var c int// math.Sqrt()接收的参数是float64类型,需要强制转换c = int(math.Sqrt(float64(a*a + b*b)))fmt.Println(c)
}
go依赖管理
配置代理,如果代理服务器有就下载,没有就去官网下载:
go env -w GOPROXY=https://goproxy.io,direct
下载依赖,这个包如果存在就更新为最新版本,不存在就下载:
go get -u
查漏补缺
go mod tidy
下面汇总一些常用的包:
github.com/golang/protobuf
mysql-driver
gorm
go-redis
kite
rocketmq/v2
与Java的对比
与Java相比好的
- 创建结构体类型的变量,内置语法支持设置其中字段,无需像Java一样手写构造函数或者调用一堆set方法
- 内置单元测试支持,约定大于配置的方式指定测试文件名/方法名,执行命令即可直接运行测试,还可以检测覆盖率
- 很多场景都有约定大于配置的思想,init方法,handler.go,单元测试,tag,
- 内置简洁web服务支持,即http库
- 内置包管理,依赖更新基于git仓库,秒级更新依赖,开发效率超高,比maven效率提高太多
- 函数多值返回,无需再为了返回多个字段,封装Java类
- 变量默认零值,string是空字符串,struct/map/pointer是nil
- 空集合range遍历,collection[index]操作,均无需判nil
- 字符串判断相等也可以用==,统一符合人的直觉,字符串零值是””而不是null
- 拒绝循环引用,编译检查发现了会报错: import cycle not allowed,保持结构可维护性
- 异常处理主要依靠error返回值, 类似于Java的检查型异常,Java项目开发中容易catch在一大段代码中,不明确是哪里抛出的, 而go的panic相当于Java的运行时错误, 作为兜底的异常处理机制, 是要避免出现的
- switch语法更加灵活, 还可以不指定变量, 当做if/else分支使用
- for和if等分支语句前,可以增加赋值语句
- 协程, 最大程度利用CPU, 状态简单,协程切换负担小
- defer延迟函数调用, 依靠单独的延迟调用栈实现
- 没有隐式类型转换, 当发生64位数值向32位数值转换时, 开发人员需要明确有没有溢出风险
- 编译非常快, 开发效率很高, 秒级启动服务, 不像spring服务启动要加载很久
与Java相比没有的
- 继承/多态, go不是面向对象语言
- 泛型, 据说官方计划会支持
- 注解, Java的注释还是特别好用的, go的
- 三目运算符, 其实可有可无
- go的命名规则推崇缩写, 基本是java禁止的命名规则, 比如Request的变量命名r, 一开始项目代码看得我相当懵逼, 都是这样的命名strconv.Itoa(),其实是string convert integer to ASCII string, 这谁能看出来
- 不像Java一样,重名类较少,直接搜索类名即可定位代码, go项目存在很多重名文件比如handler.go存在几十个, 搜索定位代码时, 比较不方便, 可以在goland用symbol定位, 可以定位到特定方法名变量名, 但整体定位代码速度还是不如Java项目快
- 还没发现类似Java对集合排序传入一个Comparetor的方便的方式
需要拓展的技术栈
| 名称 | 描述 | 学习资料 |
|---|---|---|
| Gin | Web开发框架 | |
| Kite、GRPC | RPC框架 | |
| Gorm | ORM框架 | https://www.topgoer.com/%E6%95%B0%E6%8D%AE%E5%BA%93%E6%93%8D%E4%BD%9C/gorm/gorm%E7%94%A8%E6%B3%95%E4%BB%8B%E7%BB%8D.html https://learnku.com/docs/gorm/v2 |
| go-redis | Redis操作框架 | https://learnku.com/docs/gorm/v2 |
| Consul | 服务发现和服务配置 | http://www.liangxiansen.cn/2017/04/06/consul/ |
| RocketMQ | 消息队列 | |
| github.com/golang/protobuf | 数据传输 | |
| go-yaml/yaml | 解析 YAML |
unsafe.sizeof()
流程控制
选择结构
if条件判断有一种特殊的写法,可以在 if 表达式之前添加一个执行语句,再根据变量值进行判断,通常可以用在判断是否存在err的情况,举个简单的例子:
if score := 65; score >= 90 {fmt.Println("A")
} else if score > 75 {fmt.Println("B")
} else {fmt.Println("C")
}
循环结构
Go 语言中的所有循环类型均可以使用for关键字来完成,
for i := 0; i < 10; i++ {fmt.Println(i)
}
for循环的初始语句和结束语句都可以省略,就变成了while条件循环,例如:
i := 0
for i < 10 {fmt.Println(i)i++
}
for循环可以通过break、goto、return、panic语句强制退出循环:
for {// 循环体语句
}
Go语言中可以使用for range遍历数组、切片、字符串、map 及通道(channel)返回值有以下规律:
- 数组、切片、字符串返回索引和值。
- map返回键和值。
- 通道(channel)只返回通道内的值。
for index, value := range a {fmt.Println(index, value)
}
switch结构
使用switch语句可方便地对大量的值进行条件判断,每一行不用break,会自动break
switch {case s == "a":fmt.Println("a")fallthroughcase s == "b":fmt.Println("b")default:fmt.Println("...")}switch finger {case 1,2,3:fmt.Println("大拇指")default:fmt.Println("无效的输入!")}
goto格式
使用goto语句能简化代码:
func gotoDemo() {for i := 0; i < 10; i++ {for j := 0; j < 10; j++ {if j == 2 {// 设置退出标签goto breakTag}fmt.Printf("%v-%v\n", i, j)}}return
// 标签
breakTag:fmt.Println("结束for循环")
}
字符串
多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.Trim | 去除两边指定字符 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
数组
https://www.cnblogs.com/sinclairni/p/14106519.html
数组介绍
数组是同一种数据类型元素的集合。 在Go语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化。
注意:
- 数组支持 “==“、”!=” 操作符,因为内存总是被初始化过的。
[n]*T表示指针数组,*[n]T表示数组指针 。
数组的初始化
初始化数组时可以使用初始化列表来设置数组元素的值。
func main() {var testArray [3]int //数组会初始化为int类型的零值var numArray = [3]int{1, 2} //使用指定的初始值完成初始化var cityArray = [3]string{"北京", "上海", "深圳"} //使用指定的初始值完成初始化
}
按照上面的方法每次都要确保提供的初始值和数组长度一致,一般情况下我们可以让编译器根据初始值的个数自行推断数组的长度,例如:
func main() {var testArray [3]intvar numArray = [...]int{1, 2}var cityArray = [...]string{"北京", "上海", "深圳"}
}
我们还可以使用指定索引值的方式来初始化数组,例如:
func main() {a := [...]int{1: 1, 3: 5}
}
数组的遍历
func main() {var a = [...]string{"北京", "上海", "深圳"}// 方法1:for循环遍历for i := 0; i < len(a); i++ {fmt.Println(a[i])}// 方法2:for range遍历for index, value := range a {fmt.Println(index, value)}
}
切片Slice
什么是切片
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合,它在声明的时候和数组最大的区别就是不用指明大小。
切片的定义
func main() {// 声明切片类型var a []string //声明一个字符串切片var b = []int{} //声明一个整型切片并初始化var c = []bool{false, true} //声明一个布尔切片并初始化var d = []bool{false, true} //声明一个布尔切片并初始化
}
使用make()函数构造切片
- T:切片的元素类型
- size:切片中元素的数量
- cap:切片的容量
func main() {a := make([]int, 2, 10)fmt.Println(a) //[0 0]fmt.Println(len(a)) //2fmt.Println(cap(a)) //10
}
append()方法为切片添加元素
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
func main() {// append()添加元素和切片扩容var numSlice []intfor i := 0; i < 10; i++ {numSlice = append(numSlice, i)fmt.Printf("%v len:%d cap:%d ptr:%p\n", numSlice, len(numSlice), cap(numSlice), numSlice)}// append()函数还支持一次性追加多个元素var citySlice []string// 追加一个元素citySlice = append(citySlice, "北京")// 追加多个元素citySlice = append(citySlice, "上海", "广州", "深圳")// 追加切片a := []string{"成都", "重庆"}citySlice = append(citySlice, a...)fmt.Println(citySlice) //[北京 上海 广州 深圳 成都 重庆]
}
从切片中删除元素
Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素,要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...), 代码如下:
func main() {// 从切片中删除元素a := []int{30, 31, 32, 33, 34, 35, 36, 37}// 要删除索引为2的元素a = append(a[:2], a[3:]...)fmt.Println(a) //[30 31 33 34 35 36 37]
}
使用copy()函数复制切片
func main() {// copy()复制切片a := []int{1, 2, 3, 4, 5}c := make([]int, 5, 5)copy(c, a) //使用copy()函数将切片a中的元素复制到切片cfmt.Println(a) //[1 2 3 4 5]fmt.Println(c) //[1 2 3 4 5]c[0] = 1000fmt.Println(a) //[1 2 3 4 5]fmt.Println(c) //[1000 2 3 4 5]
}
切片遍历
切片的遍历方式和数组是一致的,支持索引遍历和for range遍历。
func main() {s := []int{1, 3, 5}for i := 0; i < len(s); i++ {fmt.Println(i, s[i])}for index, value := range s {fmt.Println(index, value)}
}
求长度和容量
- 使用内置的
len()函数求长度 - 使用内置的
cap()函数求切片的容量。
一些注意点
- 拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,
Map集合
map的基本使用,当value是interface{}类型的时候,表示可以是任何类型
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。
map定义
Go语言中 map的定义语法如下:
map[KeyType]ValueType
- KeyType:表示键的类型。
- ValueType:表示键对应的值的类型。
map类型的变量默认初始值为nil,需要使用make()函数来分配内存。语法为:
make(map[KeyType]ValueType, [cap])
其中cap表示map的容量,该参数虽然不是必须的,但是应该在初始化map的时候就为其指定一个合适的容量。
map基本使用
map中的数据都是成对出现的,map的基本使用示例代码如下:
func main() {scoreMap := make(map[string]int, 8)scoreMap["张三"] = 90scoreMap["小明"] = 100fmt.Println(scoreMap)fmt.Println(scoreMap["小明"])fmt.Printf("type of a:%T\n", scoreMap)
}
map也支持在声明的时候填充元素,例如:
func main() {userInfo := map[string]string{"username": "沙河小王子","password": "123456",}fmt.Println(userInfo) //
}
判断某个键是否存在
Go语言中有个判断map中键是否存在的特殊写法,格式如下:
value, ok := map[key]
举个例子:
func main() {scoreMap := make(map[string]int)scoreMap["张三"] = 90scoreMap["小明"] = 100// 如果key存在ok为true,v为对应的值;不存在ok为false,v为值类型的零值v, ok := scoreMap["张三"]if ok {fmt.Println(v)} else {fmt.Println("查无此人")}
}
map的遍历
Go语言中使用for range遍历map。
func main() {scoreMap := make(map[string]int)scoreMap["张三"] = 90scoreMap["小明"] = 100scoreMap["娜扎"] = 60for k, v := range scoreMap {fmt.Println(k, v)}
}
但我们只想遍历key的时候,可以按下面的写法:
func main() {scoreMap := make(map[string]int)scoreMap["张三"] = 90scoreMap["小明"] = 100scoreMap["娜扎"] = 60for k := range scoreMap {fmt.Println(k)}
}
注意: 遍历map时的元素顺序与添加键值对的顺序无关。
使用delete()函数删除键值对
使用delete()内建函数从map中删除一组键值对,delete()函数的格式如下:
delete(map, key)
- map:表示要删除键值对的map
- key:表示要删除的键值对的键
按照指定顺序遍历map
func main() {rand.Seed(time.Now().UnixNano()) //初始化随机数种子var scoreMap = make(map[string]int, 200)for i := 0; i < 100; i++ {key := fmt.Sprintf("stu%02d", i) //生成stu开头的字符串value := rand.Intn(100) //生成0~99的随机整数scoreMap[key] = value}//取出map中的所有key存入切片keysvar keys = make([]string, 0, 200)for key := range scoreMap {keys = append(keys, key)}//对切片进行排序sort.Strings(keys)//按照排序后的key遍历mapfor _, key := range keys {fmt.Println(key, scoreMap[key])}
}
元素为map类型的切片
下面的代码演示了切片中的元素为map类型时的操作:
func main() {var mapSlice = make([]map[string]string, 3)for index, value := range mapSlice {fmt.Printf("index:%d value:%v\n", index, value)}fmt.Println("after init")// 对切片中的map元素进行初始化mapSlice[0] = make(map[string]string, 10)mapSlice[0]["name"] = "小王子"mapSlice[0]["password"] = "123456"mapSlice[0]["address"] = "沙河"for index, value := range mapSlice {fmt.Printf("index:%d value:%v\n", index, value)}
}
值为切片类型的map
下面的代码演示了map中值为切片类型的操作:
func main() {var sliceMap = make(map[string][]string, 3)fmt.Println(sliceMap)fmt.Println("after init")key := "中国"value, ok := sliceMap[key]if !ok {value = make([]string, 0, 2)}value = append(value, "北京", "上海")sliceMap[key] = valuefmt.Println(sliceMap)
}
函数
函数参数
类型简写
函数的参数中如果相邻变量的类型相同,则可以省略类型,例如:
func intSum(x, y int) int {return x + y
}
上面的代码中,intSum函数有两个参数,这两个参数的类型均为int,因此可以省略x的类型,因为y后面有类型说明,x参数也是该类型。
可变参数
可变参数是指函数的参数数量不固定,Go语言中的可变参数通过在参数名后加...来标识,通常情况下可变参数要作为函数的最后一个参数,本质上函数的可变参数是通过切片来实现的:
func intSum3(x int, y ...int) int {fmt.Println(x, y)sum := xfor _, v := range y {sum = sum + v}return sum
}
返回值
多返回值
Go语言中函数支持多返回值,函数如果有多个返回值时必须用()将所有返回值包裹起来。
func calc(x, y int) (int, int) {sum := x + ysub := x - yreturn sum, sub
}
返回值命名
函数定义时可以给返回值命名,并在函数体中直接使用这些变量,最后通过return关键字返回。
func calc(x, y int) (sum, sub int) {sum = x + ysub = x - yreturn
}
返回值补充
当我们的一个函数返回值类型为slice时,nil可以看做是一个有效的slice,没必要显示返回一个长度为0的切片。
func someFunc(x string) []int {if x == "" {return nil // 没必要返回[]int{}}...
}
全局变量与局部变量
-
全局变量:全局变量是定义在函数外部的变量,它在程序整个运行周期内都有效, 在函数中可以访问到全局变量。注意,需要使用
var去声明,而不能直接使用:= -
局部变量:函数内定义的变量无法在该函数外使用、if/for的局部变量不能跳出当前作用域使用,如果局部变量和全局变量重名,优先访问局部变量。
函数类型与变量
定义函数类型
我们可以使用type关键字来定义一个函数类型,具体格式如下:
type calculation func(int, int) int
上面语句定义了一个calculation类型,它是一种函数类型,这种函数接收两个int类型的参数并且返回一个int类型的返回值。
简单来说,凡是满足这个条件的函数都是calculation类型的函数,例如下面的add和sub是calculation类型。
func add(x, y int) int {return x + y
}func sub(x, y int) int {return x - y
}
add和sub都能赋值给calculation类型的变量。
var c calculation
c = add
函数类型变量
我们可以声明函数类型的变量并且为该变量赋值:
func main() {var c calculation // 声明一个calculation类型的变量cc = add // 把add赋值给cfmt.Printf("type of c:%T\n", c) // type of c:main.calculationfmt.Println(c(1, 2)) // 像调用add一样调用cf := add // 将函数add赋值给变量f1fmt.Printf("type of f:%T\n", f) // type of f:func(int, int) intfmt.Println(f(10, 20)) // 像调用add一样调用f
}
高阶函数
函数作为参数
函数可以作为参数:
func add(x, y int) int {return x + y
}
func calc(x, y int, op func(int, int) int) int {return op(x, y)
}
func main() {ret2 := calc(10, 20, add)fmt.Println(ret2) //30
}
函数作为返回值
函数也可以作为返回值:
func do(s string) (func(int, int) int, error) {switch s {case "+":return add, nilcase "-":return sub, nildefault:err := errors.New("无法识别的操作符")return nil, err}
}
匿名函数和闭包
匿名函数
匿名函数就是没有函数名的函数,多用于实现回调函数和闭包,匿名函数的定义格式如下:
func(参数)(返回值){函数体
}
匿名函数因为没有函数名,所以没办法像普通函数那样调用,所以匿名函数需要保存到某个变量或者作为立即执行函数:
func main() {// 将匿名函数保存到变量add := func(x, y int) {fmt.Println(x + y)}add(10, 20) // 通过变量调用匿名函数//自执行函数:匿名函数定义完加()直接执行func(x, y int) {fmt.Println(x + y)}(10, 20)
}
闭包
闭包指的是一个函数和与其相关的引用环境组合而成的实体,即闭包=函数+引用环境,可以理解为闭包就是把函数作为了返回值
func adder() func(int) int {var x intreturn func(y int) int {x += yreturn x}
}
func main() {var f = adder()fmt.Println(f(10)) //10fmt.Println(f(20)) //30fmt.Println(f(30)) //60f1 := adder()fmt.Println(f1(40)) //40fmt.Println(f1(50)) //90
}
变量f是一个函数并且它引用了其外部作用域中的x变量,此时f就是一个闭包。 在f的生命周期内,变量x也一直有效。 闭包进阶示例1:
func adder2(x int) func(int) int {return func(y int) int {x += yreturn x}
}
func main() {var f = adder2(10)fmt.Println(f(10)) //20fmt.Println(f(20)) //40fmt.Println(f(30)) //70f1 := adder2(20)fmt.Println(f1(40)) //60fmt.Println(f1(50)) //110
}
闭包其实并不复杂,只要牢记闭包=函数+引用环境。
defer语句
- Go语言中的
defer语句会将其后面跟随的语句在函数return后执行 - 在
defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行 defer语句能非常方便的处理资源释放问题,例如:资源清理、文件关闭、解锁及记录时间等
举个例子:
func main() {fmt.Println("start")defer fmt.Pritln(1)defer fmt.Println(2)defer fmt.Println(3)fmt.Println("end")
}
输出结果:
start
end
3
2
1
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前。具体如下图所示:
内置函数介绍
| 内置函数 | 介绍 |
|---|---|
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针 |
| make | 用来分配内存,主要用来分配引用类型,比如chan、map、slice |
| append | 用来追加元素到数组、slice中 |
| panic和recover | 用来做错误处理 |
panic/recover
Go语言中目前是没有异常机制,但是使用panic/recover模式来处理错误。 panic可以在任何地方引发,但recover只有在defer调用的函数中有效。 首先来看一个例子:
func funcA() {panic("panic in B")
}func main() {funcA()
}
程序运行期间funcB中引发了panic导致程序崩溃,异常退出了。这个时候我们就可以通过recover将程序恢复回来,继续往后执行。
func funcB() {defer func() {err := recover()//如果程序出出现了panic错误,可以通过recover恢复过来if err != nil {fmt.Println("recover in B")}}()panic("panic in B")
}func main() {funcB()
}
注意:
recover()必须搭配defer使用。defer一定要在可能引发panic的语句之前定义。
指针
简单使用
取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值,变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址(&)操作,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
func modify1(x int) {x = 100
}func modify2(x *int) {*x = 100
}func main() {a := 10modify1(a)fmt.Println(a) // 10modify2(&a)fmt.Println(a) // 100
}
new与make的区别
- 二者都是用来做内存分配的。
- make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
- 而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
结构体
方法和接收者
Go语言中的方法(Method)是一种作用于特定类型变量的函数,方法与函数的区别是,函数不属于任何类型,方法属于特定的类型,这种特定类型变量叫做接收者(Receiver)。
指针类型的接收者
指针类型的接收者由一个结构体的指针组成,由于指针的特性,调用方法时修改接收者指针的任意成员变量,在方法结束后,修改都是有效的,通常情况下我们也会这样使用
// SetAge 设置p的年龄
// 使用指针接收者
func (p *Person) SetAge(newAge int8) {p.age = newAge
}
调用该方法:
func main() {p1 := NewPerson("小王子", 25)fmt.Println(p1.age) // 25p1.SetAge(30)fmt.Println(p1.age) // 30
}
值类型的接收者
当方法作用于值类型接收者时,Go语言会在代码运行时将接收者的值复制一份。在值类型接收者的方法中可以获取接收者的成员值,但修改操作只是针对副本,无法修改接收者变量本身。
// 使用值接收者
func (p Person) SetAge2(newAge int8) {p.age = newAge
}func main() {p1 := NewPerson("小王子", 25)p1.Dream()fmt.Println(p1.age) // 25p1.SetAge2(30) // (*p1).SetAge2(30)fmt.Println(p1.age) // 25
}
任意类型添加方法
在Go语言中,接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法,我们基于内置的int类型使用type关键字可以定义新的自定义类型,然后为我们的自定义类型添加方法。
//MyInt 将int定义为自定义MyInt类型
type MyInt int//SayHello 为MyInt添加一个SayHello的方法
func (m MyInt) SayHello() {fmt.Println("Hello, 我是一个int。")
}
func main() {var m1 MyIntm1.SayHello() //Hello, 我是一个int。m1 = 100fmt.Printf("%#v %T\n", m1, m1) //100 main.MyInt
}
结构体的匿名字段
结构体允许其成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为匿名字段。
//Person 结构体Person类型
type Person struct {stringint
}func main() {p1 := Person{"小王子",18,}fmt.Printf("%#v\n", p1) //main.Person{string:"北京", int:18}fmt.Println(p1.string, p1.int) //北京 18
}
**注意:**这里匿名字段的说法并不代表没有字段名,而是默认会采用类型名作为字段名,结构体要求字段名称必须唯一,因此一个结构体中同种类型的匿名字段只能有一个。
嵌套结构体
一个结构体中可以嵌套包含另一个结构体或结构体指针,就像下面的示例代码那样。
//Address 地址结构体
type Address struct {Province stringCity string
}//User 用户结构体
type User struct {Name stringGender stringAddress Address
}func main() {user1 := User{Name: "小王子",Gender: "男",Address: Address{Province: "山东",City: "威海",},}
}
嵌套匿名字段
当访问结构体成员时会先在结构体中查找该字段,找不到再去嵌套的匿名字段中查找。,上面user结构体中嵌套的Address结构体也可以采用匿名字段的方式,例如:
//Address 地址结构体
type Address struct {Province stringCity string
}//User 用户结构体
type User struct {Name stringGender stringAddress //匿名字段
}func main() {var user2 Useruser2.Name = "小王子"user2.Gender = "男"user2.Address.Province = "山东" // 匿名字段默认使用类型名作为字段名user2.City = "威海" // 匿名字段可以省略fmt.Printf("user2=%#v\n", user2) //user2=main.User{Name:"小王子", Gender:"男", Address:main.Address{Province:"山东", City:"威海"}}
}
嵌套结构体的字段名冲突
嵌套结构体内部可能存在相同的字段名。在这种情况下为了避免歧义需要通过指定具体的内嵌结构体字段名。
//Address 地址结构体
type Address struct {CreateTime string
}//Email 邮箱结构体
type Email struct {CreateTime string
}//User 用户结构体
type User struct {AddressEmail
}func main() {var user3 User// user3.CreateTime = "2019" //ambiguous selector user3.CreateTimeuser3.Address.CreateTime = "2000" //指定Address结构体中的CreateTimeuser3.Email.CreateTime = "2000" //指定Email结构体中的CreateTime
}
结构体的“继承”
Go语言中使用结构体也可以实现其他编程语言中面向对象的继承。
//Animal 动物
type Animal struct {name string
}func (a *Animal) move() {fmt.Printf("%s会动!\n", a.name)
}//Dog 狗
type Dog struct {Feet int8*Animal //通过嵌套匿名结构体实现继承
}func (d *Dog) wang() {fmt.Printf("%s会汪汪汪~\n", d.name)
}func main() {d1 := &Dog{Feet: 4,Animal: &Animal{ //注意嵌套的是结构体指针name: "乐乐",},}d1.wang() //乐乐会汪汪汪~d1.move() //乐乐会动!
}
结构体字段的可见性
结构体中字段大写开头表示可公开访问,小写表示私有(仅在定义当前结构体的包中可访问)。
结构体与JSON序列化
序列化与反序列化
func main() {//JSON序列化:结构体-->JSON格式的字符串data, _ := json.Marshal(c)fmt.Printf("json:%s\n", data)//JSON反序列化:JSON格式的字符串-->结构体str := `xxxx`c1 := &Class{}_ = json.Unmarshal([]byte(str), c1)
}
结构体标签(Tag)
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来,例如我们为Student结构体的每个字段定义json序列化时使用的Tag:
//Student 学生
type Student struct {ID int `json:"id"` //通过指定tag实现json序列化该字段时的keyGender string //json序列化是默认使用字段名作为keyname string //私有不能被json包访问Address string `address,omitempty`//如果这个字段为空,序列化时就不包含这个字段
}func main() {s1 := Student{ID: 1,Gender: "男",name: "沙河娜扎",}data, err := json.Marshal(s1)fmt.Printf("json str:%s\n", data) //json str:{"id":1,"Gender":"男"}
}
结构体和方法补充知识点
因为slice和map这两种数据类型都包含了指向底层数据的指针,因此我们在需要复制它们时要特别注意。我们来看下面的例子:
type Person struct {name stringage int8dreams []string
}func (p *Person) SetDreams(dreams []string) {p.dreams = dreams
}func main() {p1 := Person{name: "小王子", age: 18}data := []string{"吃饭", "睡觉", "打豆豆"}p1.SetDreams(data)// 你真的想要修改 p1.dreams 吗?data[1] = "不睡觉"fmt.Println(p1.dreams) // ?
}
正确的做法是在方法中使用传入的slice的拷贝进行结构体赋值。
func (p *Person) SetDreams(dreams []string) {p.dreams = make([]string, len(dreams))copy(p.dreams, dreams)
}
接口
接口的定义
Go语言中每个接口由数个方法(零个或多个)组成,接口的定义格式如下:
type 接口类型名 interface{方法名1( 参数列表1 ) 返回值列表1方法名2( 参数列表2 ) 返回值列表2
}
举个例子:
type writer interface{Write([]byte) error
}
- 接口名:使用
type将接口定义为自定义的类型名。Go语言的接口在命名时,一般会在单词后面添加er,如有写操作的接口叫Writer,有字符串功能的接口叫Stringer等。接口名最好要能突出该接口的类型含义。 - 方法名:当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问。
- 参数列表、返回值列表:参数列表和返回值列表中的参数变量名可以省略。
实现接口的条件
一个对象只要全部实现了接口中的方法,那么就实现了这个接口
// Sayer 接口
type Sayer interface {say()
}// 定义两个结构体
type dog struct {}
type cat struct {}// dog实现了Sayer接口
func (d dog) say() {fmt.Println("汪汪汪")
}
// cat实现了Sayer接口
func (c cat) say() {fmt.Println("喵喵喵")
}
接口类型变量
接口类型变量能够存储所有实现了该接口的实例
func main() {var x Sayer // 声明一个Sayer类型的变量xa := cat{} // 实例化一个catb := dog{} // 实例化一个dogx = a // 可以把cat实例直接赋值给xx.say() // 喵喵喵x = b // 可以把dog实例直接赋值给xx.say() // 汪汪汪
}
值接收者和指针接收者实现接口的区别
使用值接收者实现接口和使用指针接收者实现接口有什么区别呢?接下来我们通过一个例子看一下其中的区别。
我们有一个Mover接口和一个dog结构体。
type Mover interface {move()
}type dog struct {}
值接收者实现接口
使用值接收者实现接口之后,不管是dog结构体还是结构体指针dog类型的变量都可以赋值给该接口变量。因为Go语言中有对指针类型变量求值的语法糖,dog指针fugui内部会自动求值*fugui。
func (d dog) move() {fmt.Println("狗会动")
}
此时实现接口的是dog类型:
func main() {var x Movervar wangcai = dog{} // 旺财是dog类型x = wangcai // x可以接收dog类型var fugui = &dog{} // 富贵是*dog类型x = fugui // x可以接收*dog类型x.move()
}
指针接收者实现接口
此时实现Mover接口的是*dog类型,所以不能给x传入dog类型的wangcai,此时x只能存储*dog类型的值。
func (d *dog) move() {fmt.Println("狗会动")
}
func main() {var x Movervar wangcai = dog{} // 旺财是dog类型x = wangcai // x不可以接收dog类型var fugui = &dog{} // 富贵是*dog类型x = fugui // x可以接收*dog类型
}
类型与接口的关系
- 一个类型可以实现多个接口
- 多个类型可以实现同一接口
接口嵌套
接口与接口间可以通过嵌套创造出新的接口。
// Sayer 接口
type Sayer interface {say()
}// Mover 接口
type Mover interface {move()
}// 接口嵌套
type animal interface {SayerMover
}
嵌套得到的接口的使用与普通接口一样,这里我们让cat实现animal接口:
type cat struct {name string
}func (c cat) say() {fmt.Println("喵喵喵")
}func (c cat) move() {fmt.Println("猫会动")
}func main() {var x animalx = cat{name: "花花"}x.move()x.say()
}
空接口
空接口的定义
空接口是指没有定义任何方法的接口,任何类型都实现了空接口,空接口类型的变量可以存储任意类型的变量。
func main() {// 定义一个空接口xvar x interface{}s := "Hello 沙河"x = sfmt.Printf("type:%T value:%v\n", x, x)i := 100x = ifmt.Printf("type:%T value:%v\n", x, x)b := truex = bfmt.Printf("type:%T value:%v\n", x, x)
}
空接口的应用
空接口作为函数的参数
使用空接口实现可以接收任意类型的函数参数。
// 空接口作为函数参数
func show(a interface{}) {fmt.Printf("type:%T value:%v\n", a, a)
}
空接口作为map的值
使用空接口实现可以保存任意值的字典。
// 空接口作为map值var studentInfo = make(map[string]interface{})studentInfo["name"] = "沙河娜扎"studentInfo["age"] = 18studentInfo["married"] = falsefmt.Println(studentInfo)
接口值/接口类型
一个接口的值(简称接口值)是由一个具体类型和具体类型的值两部分组成的,这两部分分别称为接口的动态类型和动态值。
接口断言语法返回两个参数,第一个参数是x转化为T类型后的变量,第二个值是一个布尔值,若为true则表示断言成功,为false则表示断言失败。
举个例子:
func main() {var x interface{}x = "Hello 沙河"v, ok := x.(string)if ok {fmt.Println(v)} else {fmt.Println("类型断言失败")}
}
上面的示例中如果要断言多次就需要写多个if判断,这个时候我们可以使用switch语句来实现:
func justifyType(x interface{}) {switch v := x.(type) {case string:fmt.Printf("x is a string,value is %v\n", v)case int:fmt.Printf("x is a int is %v\n", v)case bool:fmt.Printf("x is a bool is %v\n", v)default:fmt.Println("unsupport type!")}
}
并发编程
并发与并行
并发:同一时间段内执行多个任务(你在用微信和两个女朋友聊天)。
并行:同一时刻执行多个任务(你和你朋友都在用微信和女朋友聊天)。
- Go语言的并发通过
goroutine实现,goroutine类似于线程,属于用户态的线程,我们可以根据需要创建成千上万个goroutine并发工作。 goroutine是由Go语言的运行时(runtime)调度完成,而线程是由操作系统调度完成。- Go语言还提供
channel在多个goroutine间进行通信。goroutine和channel是 Go 语言秉承的 CSP(Communicating Sequential Process)并发模式的重要实现基础。
goroutine
goroutine的概念类似于线程,但 goroutine是由Go的运行时(runtime)调度和管理的。Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能——goroutine,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个goroutine去执行这个函数就可以了,就是这么简单粗暴。
启动单个goroutine
启动goroutine的方式非常简单,只需要在调用的函数(普通函数和匿名函数)前面加上一个go关键字:
func hello() {fmt.Println("Hello Goroutine!")
}
func main() {go hello() // 启动另外一个goroutine去执行hello函数fmt.Println("main goroutine done!")
}
执行结果只打印了main goroutine done!,并没有打印Hello Goroutine!,因为在程序启动时,Go程序就会为main()函数创建一个默认的goroutine。
当main()函数返回的时候该goroutine就结束了,所有在main()函数中启动的goroutine会一同结束,main函数所在的goroutine就像是权利的游戏中的夜王,其他的goroutine都是异鬼,夜王一死它转化的那些异鬼也就全部GG了。所以我们要想办法让main函数等一等hello函数,最简单粗暴的方式就是time.Sleep了。
func hello() {fmt.Println("Hello Goroutine!")
}
func main() {go hello() // 启动另外一个goroutine去执行hello函数fmt.Println("main goroutine done!")time.Sleep(time.Second)
}
执行上面的代码你会发现,这一次先打印main goroutine done!,然后紧接着打印Hello Goroutine!,因为我们在创建新的goroutine的时候需要花费一些时间,而此时main函数所在的goroutine是继续执行的。
启动多个goroutine
在Go语言中实现并发就是这样简单,我们还可以启动多个goroutine,这里使用了sync.WaitGroup来实现goroutine的同步
var wg sync.WaitGroupfunc hello(i int) {defer wg.Done() // goroutine结束就登记-1fmt.Println("Hello Goroutine!", i)
}
func main() {for i := 0; i < 10; i++ {wg.Add(1) // 启动一个goroutine就登记+1go hello(i)}wg.Wait() // 等待所有登记的goroutine都结束
}
goroutine与线程
对应的关系
Go语言中的操作系统线程和goroutine的关系:
- 一个操作系统线程对应用户态多个goroutine。
- go程序可以同时使用多个操作系统线程。
- goroutine和OS线程是多对多的关系,即m:n。
可增长的栈
OS线程(操作系统线程)一般都有固定的栈内存(通常为2MB),一个goroutine的栈在其生命周期开始时只有很小的栈(典型情况下2KB),goroutine的栈不是固定的,他可以按需增大和缩小,goroutine的栈大小限制可以达到1GB,虽然极少会用到这么大,所以在Go语言中一次创建十万左右的goroutine也是可以的。
设置占用CPU的核数
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个OS线程来同时执行Go代码。默认值是机器上的CPU核心数。例如在一个8核心的机器上,调度器会把Go代码同时调度到8个OS线程上(GOMAXPROCS是m:n调度中的n),可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数。
func a() {for i := 1; i < 10; i++ {fmt.Println("A:", i)}
}
func b() {for i := 1; i < 10; i++ {fmt.Println("B:", i)}
}
func main() {runtime.GOMAXPROCS(2)go a()go b()time.Sleep(time.Second)
}
channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
创建channel
channel是一种类型,一种引用类型。声明通道类型的格式如下:
var ch1 chan int // 声明一个传递整型的通道
var ch2 chan bool // 声明一个传递布尔型的通道
var ch3 chan []int // 声明一个传递int切片的通道
通道是引用类型,通道类型的空值是nil,声明后需要使用make函数初始化之后才能使用,第二个参数是channel的缓冲大小,是可选的参数:
ch4 := make(chan int,1024)
ch5 := make(chan bool)
ch6 := make(chan []int)
channel操作
通道有发送(send)、接收(receive)和关闭(close)三种操作,发送和接收都使用<-符号,现在我们先使用以下语句定义一个通道:
ch := make(chan int)
发送
将一个值发送到通道中。
ch <- 10 // 把10发送到ch中
接收
从一个通道中接收值。
x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果
关闭
我们通过调用内置的close函数来关闭通道。
close(ch)
关于关闭通道需要注意的事情是,只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
- 对一个关闭的通道再发送值就会导致panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致panic。
无缓冲的通道
无缓冲的通道又称为阻塞的通道:
func main() {ch := make(chan int)ch <- 10fmt.Println("发送成功")
}
上面这段代码能够通过编译,但是执行的时候会出现deadlock错误,因为我们使用ch := make(chan int)创建的是无缓冲的通道,无缓冲的通道只有在有人接收值的时候才能发送值。就像你住的小区没有快递柜和代收点,快递员给你打电话必须要把这个物品送到你的手中,简单来说就是无缓冲的通道必须有接收才能发送。上面的代码会阻塞在ch <- 10这一行代码形成死锁,那如何解决这个问题呢?
可以启用一个goroutine去接收值,也可以创建有缓冲的通道,例如:
func recv(c chan int) {ret := <-cfmt.Println("接收成功", ret)
}
func main() {ch := make(chan int)go recv(ch) // 启用goroutine从通道接收值ch <- 10fmt.Println("发送成功")
}
无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。相反,如果接收操作先执行,接收方的goroutine将阻塞,直到另一个goroutine在该通道上发送一个值。使用无缓冲通道进行通信将导致发送和接收的goroutine同步化。因此,无缓冲通道也被称为同步通道。
有缓冲的通道
我们可以在使用make函数初始化通道的时候为其指定通道的容量,只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。就像你小区的快递柜只有那么个多格子,格子满了就装不下了,就阻塞了,等到别人取走一个快递员就能往里面放一个。我们可以使用内置的len函数获取通道内元素的数量,使用cap函数获取通道的容量,虽然我们很少会这么做。
func main() {ch := make(chan int, 1) // 创建一个容量为1的有缓冲区通道ch <- 10fmt.Println("发送成功")
}
for range从通道循环取值
当向通道中发送完数据时,我们可以通过close函数来关闭通道。当通道被关闭时,再往该通道发送值会引发panic,从该通道取值的操作会先取完通道中的值,再然后取到的值一直都是对应类型的零值。那如何判断一个通道是否被关闭了呢?
有两种方式在接收值的时候判断该通道是否被关闭,不过我们通常使用的是for range的方式。使用for range遍历通道,当通道被关闭的时候就会退出for range。
func main() {ch1 := make(chan int)ch2 := make(chan int)go func() {for i := 0; i < 100; i++ {ch1 <- i}close(ch1)}()// 方法一go func() {for {i, ok := <-ch1 // 通道关闭后再取值ok=falseif !ok {break}ch2 <- i * i}close(ch2)}()// 方法二for i := range ch2 { // 通道关闭后会退出for range循环fmt.Println(i)}
}
单向通道
有的时候我们会将通道作为参数在多个任务函数间传递,很多时候我们在不同的任务函数中使用通道都会对其进行限制,比如限制通道在函数中只能发送或只能接收,Go语言中提供了单向通道来处理这种情况
在函数传参及任何赋值操作中可以将双向通道转换为单向通道,但反过来是不可以的
chan<- int是一个只写单向通道(只能对其写入int类型值),可以对其执行发送操作但是不能执行接收操作;<-chan int是一个只读单向通道(只能从其读取int类型值),可以对其执行接收操作但是不能执行发送操作。
func counter(out chan<- int) {for i := 0; i < 100; i++ {out <- i}close(out)
}func squarer(out chan<- int, in <-chan int) {for i := range in {out <- i * i}close(out)
}
func printer(in <-chan int) {for i := range in {fmt.Println(i)}
}func main() {ch1 := make(chan int)ch2 := make(chan int)go counter(ch1)go squarer(ch2, ch1)printer(ch2)
}
通道总结
关闭已经关闭的channel也会引发panic,channel常见的异常总结:
| channel | nil | 非空 | 空 | 满 | 没满 |
|---|---|---|---|---|---|
| 接受 | 阻塞 | 接收值 | 阻塞 | 接收值 | 接收值 |
| 发送 | 阻塞 | 发送值 | 发送值 | 阻塞 | 发送值 |
| 关闭 | panic | 关闭成功,读完数据后返回零值 | 关闭成功,返回零值 | 关闭成功,读完数据后返回零值 | 关闭成功,读完数据后返回零值 |
worker pool(goroutine池)
在工作中我们通常会使用可以指定启动的goroutine数量——worker pool模式,控制goroutine的数量,防止goroutine泄漏和暴涨,一个简易的work pool示例代码如下:
func worker(id int, jobs <-chan int, results chan<- int) {for j := range jobs {fmt.Printf("worker:%d start job:%d\n", id, j)time.Sleep(time.Second)fmt.Printf("worker:%d end job:%d\n", id, j)results <- j * 2}
}func main() {jobs := make(chan int, 100)results := make(chan int, 100)// 开启3个goroutinefor w := 1; w <= 3; w++ {go worker(w, jobs, results)}// 5个任务for j := 1; j <= 5; j++ {jobs <- j}close(jobs)// 输出结果for a := 1; a <= 5; a++ {<-results}
}
select多路复用
在某些场景下我们需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以接收将会发生阻塞,为了应对这种场景,Go内置了select关键字,可以同时响应多个通道的操作。
select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句:
select{case <-ch1:...case data := <-ch2:...case ch3<-data:...default:默认操作
}
举个小例子来演示下select的使用:
func main() {ch := make(chan int, 1)for i := 0; i < 10; i++ {select {case x := <-ch:fmt.Println(x)case ch <- i:}}
}
使用select语句能提高代码的可读性。
- 可处理一个或多个channel的发送/接收操作。
- 如果多个
case同时满足,select会随机选择一个。 - 对于没有
case的select{}会一直等待,可用于阻塞main函数。
并发安全和锁
互斥锁
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个goroutine可以访问共享资源。Go语言中使用sync包的Mutex类型来实现互斥锁。
使用互斥锁能够保证同一时间有且只有一个goroutine进入临界区,其他的goroutine则在等待锁;当互斥锁释放后,等待的goroutine才可以获取锁进入临界区,多个goroutine同时等待一个锁时,唤醒的策略是随机的。
var x int64
var wg sync.WaitGroup
var lock sync.Mutexfunc add() {for i := 0; i < 5000; i++ {lock.Lock() // 加锁x = x + 1lock.Unlock() // 解锁}wg.Done()
}
func main() {wg.Add(2)go add()go add()wg.Wait()fmt.Println(x)
}
读写互斥锁
互斥锁是完全互斥的,但是有很多实际的场景下是读多写少的,当我们并发的去读取一个资源不涉及资源修改的时候是没有必要加锁的,这种场景下使用读写锁是更好的一种选择。读写锁在Go语言中使用sync包中的RWMutex类型。
读写锁分为两种:读锁和写锁。当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待。
var (x int64wg sync.WaitGrouplock sync.Mutexrwlock sync.RWMutex
)func write() {// lock.Lock() // 加互斥锁rwlock.Lock() // 加写锁x = x + 1time.Sleep(10 * time.Millisecond) // 假设读操作耗时10毫秒rwlock.Unlock() // 解写锁// lock.Unlock() // 解互斥锁wg.Done()
}func read() {// lock.Lock() // 加互斥锁rwlock.RLock() // 加读锁time.Sleep(time.Millisecond) // 假设读操作耗时1毫秒rwlock.RUnlock() // 解读锁// lock.Unlock() // 解互斥锁wg.Done()
}func main() {start := time.Now()for i := 0; i < 10; i++ {wg.Add(1)go write()}for i := 0; i < 1000; i++ {wg.Add(1)go read()}wg.Wait()end := time.Now()fmt.Println(end.Sub(start))
}
sync.WaitGroup
在代码中生硬的使用time.Sleep肯定是不合适的,Go语言中可以使用sync.WaitGroup来实现并发任务的同步,需要注意sync.WaitGroup是一个结构体,传递的时候要传递指针, sync.WaitGroup有以下几个方法:
| 方法名 | 功能 |
|---|---|
| (wg * WaitGroup) Add(delta int) | 计数器+delta |
| (wg *WaitGroup) Done() | 计数器-1 |
| (wg *WaitGroup) Wait() | 阻塞直到计数器变为0 |
sync.WaitGroup内部维护着一个计数器,计数器的值可以增加和减少。例如当我们启动了N 个并发任务时,就将计数器值增加N。每个任务完成时通过调用Done()方法将计数器减1。通过调用Wait()来等待并发任务执行完,当计数器值为0时,表示所有并发任务已经完成。
var wg sync.WaitGroupfunc hello() {defer wg.Done()fmt.Println("Hello Goroutine!")
}
func main() {wg.Add(1)go hello() // 启动另外一个goroutine去执行hello函数fmt.Println("main goroutine done!")wg.Wait()
}
sync.Once
这是一个进阶知识点,在编程的很多场景下我们需要确保某些操作在高并发的场景下只执行一次,例如只加载一次配置文件、只关闭一次通道等。Go语言中的sync包中提供了一个针对只执行一次场景的解决方案——sync.Once,它只有一个Do方法,其签名如下:
func (o *Once) Do(f func()) {}
sync.Once其实内部包含一个互斥锁和一个布尔值,互斥锁保证布尔值和数据的安全,而布尔值用来记录初始化是否完成。这样设计就能保证初始化操作的时候是并发安全的并且初始化操作也不会被执行多次。
备注:如果要执行的函数f需要传递参数就需要搭配闭包来使用。
加载配置文件示例
延迟一个开销很大的初始化操作到真正用到它的时候再执行是一个很好的实践。因为预先初始化一个变量(比如在init函数中完成初始化)会增加程序的启动耗时,而且有可能实际执行过程中这个变量没有用上,那么这个初始化操作就不是必须要做的。我们来看一个例子:
var icons map[string]image.Imagefunc loadIcons() {icons = map[string]image.Image{"left": loadIcon("left.png"),"up": loadIcon("up.png"),"right": loadIcon("right.png"),"down": loadIcon("down.png"),}
}// Icon 被多个goroutine调用时不是并发安全的
func Icon(name string) image.Image {if icons == nil {loadIcons()}return icons[name]
}
多个goroutine并发调用Icon函数时不是并发安全的,现代的编译器和CPU可能会在保证每个goroutine都满足串行一致的基础上自由地重排访问内存的顺序。loadIcons函数可能会被重排为以下结果:
func loadIcons() {icons = make(map[string]image.Image)icons["left"] = loadIcon("left.png")icons["up"] = loadIcon("up.png")icons["right"] = loadIcon("right.png")icons["down"] = loadIcon("down.png")
}
在这种情况下就会出现即使判断了icons不是nil也不意味着变量初始化完成了。考虑到这种情况,我们能想到的办法就是添加互斥锁,保证初始化icons的时候不会被其他的goroutine操作,但是这样做又会引发性能问题,使用sync.Once改造的示例代码如下:
var icons map[string]image.Imagevar loadIconsOnce sync.Oncefunc loadIcons() {icons = map[string]image.Image{"left": loadIcon("left.png"),"up": loadIcon("up.png"),"right": loadIcon("right.png"),"down": loadIcon("down.png"),}
}// Icon 是并发安全的
func Icon(name string) image.Image {loadIconsOnce.Do(loadIcons)return icons[name]
}
并发安全的单例模式
下面是借助sync.Once实现的并发安全的单例模式:
type singleton struct {}var instance *singleton
var once sync.Oncefunc GetInstance() *singleton {once.Do(func() {instance = &singleton{}})return instance
}
sync.Map
Go语言中内置的map不是并发安全的,当并发多了之后代码就会报fatal error: concurrent map writes错误。像这种场景下就需要为map加锁来保证并发的安全性了。
Go语言的sync包中提供了一个开箱即用的并发安全版map——sync.Map。开箱即用表示不用像内置的map一样使用make函数初始化就能直接使用。同时sync.Map内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法。
var m = sync.Map{}func main() {wg := sync.WaitGroup{}for i := 0; i < 20; i++ {wg.Add(1)go func(n int) {key := strconv.Itoa(n)m.Store(key, n)value, _ := m.Load(key)fmt.Printf("k=:%v,v:=%v\n", key, value)wg.Done()}(i)}wg.Wait()
}
原子操作
在上面的代码中的我们通过锁操作来实现同步。而锁机制的底层是基于原子操作的,其一般直接通过CPU指令实现。Go语言中原子操作由内置的标准库sync/atomic提供。
atomic包提供了底层的原子级内存操作,对于同步算法的实现很有用,这些函数必须谨慎地保证正确使用。除了某些特殊的底层应用,使用通道或者sync包的函数/类型实现同步更好。
atomic包
| 方法 | 解释 |
|---|---|
| func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) | 读取操作 |
| func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) | 写入操作 |
| func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) | 修改操作 |
| func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) | 交换操作 |
| func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) | 比较并交换操作 |
互斥锁与原子操作比较
package mainimport ("fmt""sync""sync/atomic""time"
)type Counter interface {Inc()Load() int64
}// 普通版
type CommonCounter struct {counter int64
}func (c CommonCounter) Inc() {c.counter++
}func (c CommonCounter) Load() int64 {return c.counter
}// 互斥锁版
type MutexCounter struct {counter int64lock sync.Mutex
}func (m *MutexCounter) Inc() {m.lock.Lock()defer m.lock.Unlock()m.counter++
}func (m *MutexCounter) Load() int64 {m.lock.Lock()defer m.lock.Unlock()return m.counter
}// 原子操作版
type AtomicCounter struct {counter int64
}func (a *AtomicCounter) Inc() {atomic.AddInt64(&a.counter, 1)
}func (a *AtomicCounter) Load() int64 {return atomic.LoadInt64(&a.counter)
}func test(c Counter) {var wg sync.WaitGroupstart := time.Now()for i := 0; i < 1000; i++ {wg.Add(1)go func() {c.Inc()wg.Done()}()}wg.Wait()end := time.Now()fmt.Println(c.Load(), end.Sub(start))
}func main() {c1 := CommonCounter{} // 非并发安全test(c1)c2 := MutexCounter{} // 使用互斥锁实现并发安全test(&c2)c3 := AtomicCounter{} // 并发安全且比互斥锁效率更高test(&c3)
}
反射
变量的内在机制
Go语言中的变量是分为两部分的:
- 类型信息:预先定义好的元信息。
- 值信息:程序运行过程中可动态变化的。
反射介绍
反射是指在程序运行期对程序本身进行访问和修改的能力。程序在编译时,变量被转换为内存地址,变量名不会被编译器写入到可执行部分。在运行程序时,程序无法获取自身的信息。
支持反射的语言可以在程序编译期将变量的反射信息,如字段名称、类型信息、结构体信息等整合到可执行文件中,并给程序提供接口访问反射信息,这样就可以在程序运行期获取类型的反射信息,并且有能力修改它们。
Go程序在运行期使用reflect包访问程序的反射信息。
在上一篇博客中我们介绍了空接口。 空接口可以存储任意类型的变量,那我们如何知道这个空接口保存的数据是什么呢? 反射就是在运行时动态的获取一个变量的类型信息和值信息。
reflect包
TypeOf
在反射中关于类型还划分为两种:类型(Type)和种类(Kind)。因为在Go语言中我们可以使用type关键字构造很多自定义类型,而种类(Kind)就是指底层的类型,但在反射中,当需要区分指针、结构体等大品种的类型时,就会用到种类(Kind)。
package mainimport ("fmt""reflect"
)type myInt int64func reflectType(x interface{}) {t := reflect.TypeOf(x)fmt.Printf("type:%v kind:%v\n", t.Name(), t.Kind())
}func main() {var a *float32 // 指针var b myInt // 自定义类型var c rune // 类型别名reflectType(a) // type: kind:ptrreflectType(b) // type:myInt kind:int64reflectType(c) // type:int32 kind:int32type person struct {name stringage int}type book struct{ title string }var d = person{name: "沙河小王子",age: 18,}var e = book{title: "《跟小王子学Go语言》"}reflectType(d) // type:person kind:structreflectType(e) // type:book kind:struct
}
Go语言的反射中像数组、切片、Map、指针等类型的变量,它们的.Name()都是返回空。
在reflect包中定义的Kind类型如下:
type Kind uint
const (Invalid Kind = iota // 非法类型Bool // 布尔型Int // 有符号整型Int8 // 有符号8位整型Int16 // 有符号16位整型Int32 // 有符号32位整型Int64 // 有符号64位整型Uint // 无符号整型Uint8 // 无符号8位整型Uint16 // 无符号16位整型Uint32 // 无符号32位整型Uint64 // 无符号64位整型Uintptr // 指针Float32 // 单精度浮点数Float64 // 双精度浮点数Complex64 // 64位复数类型Complex128 // 128位复数类型Array // 数组Chan // 通道Func // 函数Interface // 接口Map // 映射Ptr // 指针Slice // 切片String // 字符串Struct // 结构体UnsafePointer // 底层指针
)
ValueOf
reflect.ValueOf()返回的是reflect.Value类型,其中包含了原始值的值信息。reflect.Value与原始值之间可以互相转换。
reflect.Value类型提供的获取原始值的方法如下:
| 方法 | 说明 |
|---|---|
| Interface() interface {} | 将值以 interface{} 类型返回,可以通过类型断言转换为指定类型 |
| Int() int64 | 将值以 int 类型返回,所有有符号整型均可以此方式返回 |
| Uint() uint64 | 将值以 uint 类型返回,所有无符号整型均可以此方式返回 |
| Float() float64 | 将值以双精度(float64)类型返回,所有浮点数(float32、float64)均可以此方式返回 |
| Bool() bool | 将值以 bool 类型返回 |
| Bytes() []bytes | 将值以字节数组 []bytes 类型返回 |
| String() string | 将值以字符串类型返回 |
通过反射获取值
func reflectValue(x interface{}) {v := reflect.ValueOf(x)k := v.Kind()switch k {case reflect.Int64:// v.Int()从反射中获取整型的原始值,然后通过int64()强制类型转换fmt.Printf("type is int64, value is %d\n", int64(v.Int()))case reflect.Float32:// v.Float()从反射中获取浮点型的原始值,然后通过float32()强制类型转换fmt.Printf("type is float32, value is %f\n", float32(v.Float()))case reflect.Float64:// v.Float()从反射中获取浮点型的原始值,然后通过float64()强制类型转换fmt.Printf("type is float64, value is %f\n", float64(v.Float()))}
}
func main() {var a float32 = 3.14var b int64 = 100reflectValue(a) // type is float32, value is 3.140000reflectValue(b) // type is int64, value is 100// 将int类型的原始值转换为reflect.Value类型c := reflect.ValueOf(10)fmt.Printf("type c :%T\n", c) // type c :reflect.Value
}
通过反射设置变量的值
想要在函数中通过反射修改变量的值,需要注意函数参数传递的是值拷贝,必须传递变量地址才能修改变量值。而反射中使用专有的Elem()方法来获取指针对应的值。
package mainimport ("fmt""reflect"
)func reflectSetValue1(x interface{}) {v := reflect.ValueOf(x)if v.Kind() == reflect.Int64 {v.SetInt(200) //修改的是副本,reflect包会引发panic}
}
func reflectSetValue2(x interface{}) {v := reflect.ValueOf(x)// 反射中使用 Elem()方法获取指针对应的值if v.Elem().Kind() == reflect.Int64 {v.Elem().SetInt(200)}
}
func main() {var a int64 = 100// reflectSetValue1(a) //panic: reflect: reflect.Value.SetInt using unaddressable valuereflectSetValue2(&a)fmt.Println(a)
}
isNil()和isValid()
IsNil()报告v持有的值是否为nil。v持有的值的分类必须是通道、函数、接口、映射、指针、切片之一;否则IsNil函数会导致panic。IsValid()返回v是否持有一个值。如果v是Value零值会返回假,此时v除了IsValid、String、Kind之外的方法都会导致panic。
IsNil()常被用于判断指针是否为空;IsValid()常被用于判定返回值是否有效,例如:
func main() {// *int类型空指针var a *intfmt.Println("var a *int IsNil:", reflect.ValueOf(a).IsNil())// nil值fmt.Println("nil IsValid:", reflect.ValueOf(nil).IsValid())// 实例化一个匿名结构体b := struct{}{}// 尝试从结构体中查找"abc"字段fmt.Println("不存在的结构体成员:", reflect.ValueOf(b).FieldByName("abc").IsValid())// 尝试从结构体中查找"abc"方法fmt.Println("不存在的结构体方法:", reflect.ValueOf(b).MethodByName("abc").IsValid())// mapc := map[string]int{}// 尝试从map中查找一个不存在的键fmt.Println("map中不存在的键:", reflect.ValueOf(c).MapIndex(reflect.ValueOf("娜扎")).IsValid())
}
结构体反射
与结构体相关的方法
任意值通过reflect.TypeOf()获得反射对象信息后,如果它的类型是结构体,可以通过反射值对象(reflect.Type)的NumField()和Field()方法获得结构体成员的详细信息。
reflect.Type中与获取结构体成员相关的的方法如下表所示。
| 方法 | 说明 |
|---|---|
| Field(i int) StructField | 根据索引,返回索引对应的结构体字段的信息。 |
| NumField() int | 返回结构体成员字段数量。 |
| FieldByName(name string) (StructField, bool) | 根据给定字符串返回字符串对应的结构体字段的信息。 |
| FieldByIndex(index []int) StructField | 多层成员访问时,根据 []int 提供的每个结构体的字段索引,返回字段的信息。 |
| FieldByNameFunc(match func(string) bool) (StructField,bool) | 根据传入的匹配函数匹配需要的字段。 |
| NumMethod() int | 返回该类型的方法集中方法的数目 |
| Method(int) Method | 返回该类型方法集中的第i个方法 |
| MethodByName(string)(Method, bool) | 根据方法名返回该类型方法集中的方法 |
StructField类型
StructField类型用来描述结构体中的一个字段的信息,StructField的定义如下:
type StructField struct {// Name是字段的名字。PkgPath是非导出字段的包路径,对导出字段该字段为""。// 参见http://golang.org/ref/spec#Uniqueness_of_identifiersName stringPkgPath stringType Type // 字段的类型Tag StructTag // 字段的标签Offset uintptr // 字段在结构体中的字节偏移量Index []int // 用于Type.FieldByIndex时的索引切片Anonymous bool // 是否匿名字段
}
遍历结构体所有字段
type student struct {Name string `json:"name"`Score int `json:"score"`
}func main() {stu1 := student{Name: "小王子",Score: 90,}t := reflect.TypeOf(stu1)fmt.Println(t.Name(), t.Kind()) // student struct// 通过for循环遍历结构体的所有字段信息for i := 0; i < t.NumField(); i++ {field := t.Field(i)fmt.Printf("name:%s index:%d type:%v json tag:%v\n", field.Name, field.Index, field.Type, field.Tag.Get("json"))}// 通过字段名获取指定结构体字段信息if scoreField, ok := t.FieldByName("Score"); ok {fmt.Printf("name:%s index:%d type:%v json tag:%v\n", scoreField.Name, scoreField.Index, scoreField.Type, scoreField.Tag.Get("json"))}
}
遍历结构体所有方法
// 给student添加两个方法 Study和Sleep(注意首字母大写)
func (s student) Study() string {msg := "好好学习,天天向上。"fmt.Println(msg)return msg
}func (s student) Sleep() string {msg := "好好睡觉,快快长大。"fmt.Println(msg)return msg
}func printMethod(x interface{}) {t := reflect.TypeOf(x)v := reflect.ValueOf(x)fmt.Println(t.NumMethod())for i := 0; i < v.NumMethod(); i++ {methodType := v.Method(i).Type()fmt.Printf("method name:%s\n", t.Method(i).Name)fmt.Printf("method:%s\n", methodType)// 通过反射调用方法传递的参数必须是 []reflect.Value 类型var args = []reflect.Value{}v.Method(i).Call(args)}
}
反射是把双刃剑
反射是一个强大并富有表现力的工具,能让我们写出更灵活的代码,但是反射不应该被滥用,原因有以下三个:
- 基于反射的代码是极其脆弱的,反射中的类型错误会在真正运行的时候才会引发panic,那很可能是在代码写完的很长时间之后。
- 大量使用反射的代码通常难以理解。
- 反射的性能低下,基于反射实现的代码通常比正常代码运行速度慢一到两个数量级。
包
可见性
如果想在一个包中引用另外一个包里的标识符(如变量、常量、类型、函数等)时,该标识符必须是对外可见的(public),在Go语言中只需要将标识符的首字母大写就可以让标识符对外可见了。
包的导入
要在代码中引用其他包的内容,需要使用import关键字导入使用的包。具体语法如下:
import "包的路径"import (别名 "包1"_ "包2""包3"
)
注意事项:
- 包名是从
$GOPATH/src/后开始计算的,使用/进行路径分隔。 - Go语言中禁止循环导入包。
- 可以为导入的包设置别名,解决包名冲突的问题
- 如果只希望导入包而不使用包内部的数据时,可以使用匿名导入包
- 匿名导入的包与其他方式导入的包一样都会被编译到可执行文件中
init()初始化函数
init()函数介绍
在Go语言程序执行时导入包语句会自动触发包内部init()函数的调用。需要注意的是: init()函数没有参数也没有返回值。 init()函数在程序运行时自动被调用执行,不能在代码中主动调用它,调用 的时机如下:
- 全局声明
- init()
- main()
init()函数执行顺序
Go语言包会从main包开始检查其导入的所有包,每个包中又可能导入了其他的包。Go编译器由此构建出一个树状的包引用关系,再根据引用顺序决定编译顺序,依次编译这些包的代码,在运行时,被最后导入的包会最先初始化并调用其init()函数, 如图所示:

测试
单测某个接口
go test -run TestGetUsersNoBadgedCountsForChatPosition
测试规则
- 单元测试的函数必须以Test开头,是公开函数
- 测试文件必须以_test.go结尾
- 单元测试文件名命名为:go文件的文件名+_test.go
- 函数名命名为:Test+测试函数名
- 测试函数必须接收一个指向testing.T类型的指针(依测试目的而定,如主要是测试性能,则用testing.B等),并且不能返回任何值
一个简单的测试
func TestAdd(t *testing.T){if sum:=Add(1,2); sum!=3{t.Error("fail")//日志一般要写成f(x)=y, want z的形式} else {t.Log("success")}
}
表格驱动测试
func TestAdd(t *testing.T){var tests = []struct{date []intwant int}{{[]int{1, 2}, 3},{[]int{2, 5}, 7},{[]int{3, 9}, 11},}for _,v := range tests{if sum:=Add(v.date[0], v.date[1]); sum!=v.want{t.Errorf("Add(%d, %d) = %d, want %d", v.date[0], v.date[1], v.date[0]+v.date[1], v.want)} else {t.Log("success")}}
}
标准库
time
os
相关文章:
Go语言基础知识学习笔记
环境准备 下载安装Golang:https://golang.google.cn/dl/ 因为国外下载速度较慢,我们需要配置国内代理 # 开启包管理工具 go env -w GO111MODULEon # 设置代理 go env -w GOPROXYhttps://goproxy.cn,direct # 设置不走 proxy 的私有仓库,多…...

Python3 错误和异常
Python3 错误和异常 作为 Python 初学者,在刚学习 Python 编程时,经常会看到一些报错信息,在前面我们没有提及,这章节我们会专门介绍。 Python 有两种错误很容易辨认:语法错误和异常。 Python assert(断…...

程序人生 - 学习和分享
文章目录记于 230217学习安排泛学AI 和 未来记于 230217 刚入行时,经常看到技术博客中,博主们分享生活,比如相亲、上班生活,甚至还有人发结婚照。这个栏目通常被称为:程序人生。 这个现象已经很久没看到了,…...

基于树莓派的智能家居项目整理
一、功能介绍 二、设计框图 三、实物展示 四、程序 一、功能介绍硬件:树莓派3B、LD3320语音识别模块、pi 摄像头、继电器组、小灯、火焰传感器、蜂鸣器、电 磁锁 项目框架: 采用了简单工厂模式的一个设计方式。稳定,拓展性…...

《洛阳冬冷》
——洛阳的冬天太冷,最暖不过你的眼神。 ******* 她拿了个画着几丛竹子的小团扇子一路分花拂柳地往前走,后面一水儿的侍女不敢出声,只得地默默跟着她。她一张脸本来生得就好看,这一怒起来竟然还更加的好看了。此时她走得太急&…...
YOLOv5简介
YOLOv5 一、输入端 1. Mosaic数据增强: CutMix 数据增强:随机生成一个裁剪框Box,裁剪掉A图中的相应位置,然后用B图相应位置的ROI放到A中被裁剪的区域中形成新的样本。采用加权求和的方式计算损失,将A区域中被cut掉的…...
【面向对象语言三大特性之 “继承”】
目录 1.继承的概念及定义 1.1继承的概念 1.2 继承定义 1.2.1定义格式 1.2.2继承关系和访问限定符 1.2.3继承基类成员访问方式的变化 2.基类和派生类对象赋值转换 3.继承中的作用域 4.派生类的默认成员函数 5.继承与友元 6. 继承与静态成员 7.复杂的菱形继承及菱形虚拟…...
Ambari2.7.5集群搭建详细流程
0 说明 本文基于本地虚拟机从零开始搭建ambari集群 1 前置条件 1.1 本地虚拟机环境 节点角色ambari-1ambari-server ambari-agentambari-2ambari-agentambari-3ambari-agent 1.2 安装包 1.3 修改主机名并配置hosts文件 hostnamectl set-hostname ambari-1 hostnamectl se…...

房产|1月全国70城房价出炉!疫情放开后你关心的城市房价有何变化
2023年1月份,70个大中城市中新房销售价格环比上涨城市个数增加;一线城市新房销售价格环比同比转涨、二三线城市环比降势趋缓,二三线城市同比下降。 | 新房/二手房12月-1月环比上涨城市数量变化 70个大中城市中,新房环比上涨城市…...

秒验 重新定义“一键登录”
现如今,一般APP在注册登录时,仍然要经历填写用户名、密码、绑定手机号等一系列传统流程,有的人认为可以通过第三方登录避免这些流程,但仍旧要经历手机验证码的环节,而且存在验证码被拦截的风险,短信费用也很…...

ZenBuster:一款功能强大的多线程跨平台URL枚举工具
关于ZenBuster ZenBuster是一款功能强大的多线程跨平台URL枚举工具,该工具基于Python开发,同时还具备暴力破解功能。 该工具适用于安全专业人员,可以在渗透测试或CTF比赛中为广大研究人员提供帮助,并收集和目标相关的各种信息。…...

2023年美赛ICM问题E:光污染 这题很好做啊!
2023年美赛ICM问题E:光污染 这题很好做啊! 我看到DS数模的分析,看似头头是道,实则GouPi不通,我出一个,用于大家…...
)
InVEST模型 | 01 InVEST模型安装(Windows10)
除了在Python Anaconda环境中进行安装InVEST模型Python安装,平时最常使用的安装方式是通过.exe直接进行安装,本节介绍的就是直接下载安装的步骤: 打开InVEST模型下载页面 链接为:https://naturalcapitalproject.stanford.edu/…...
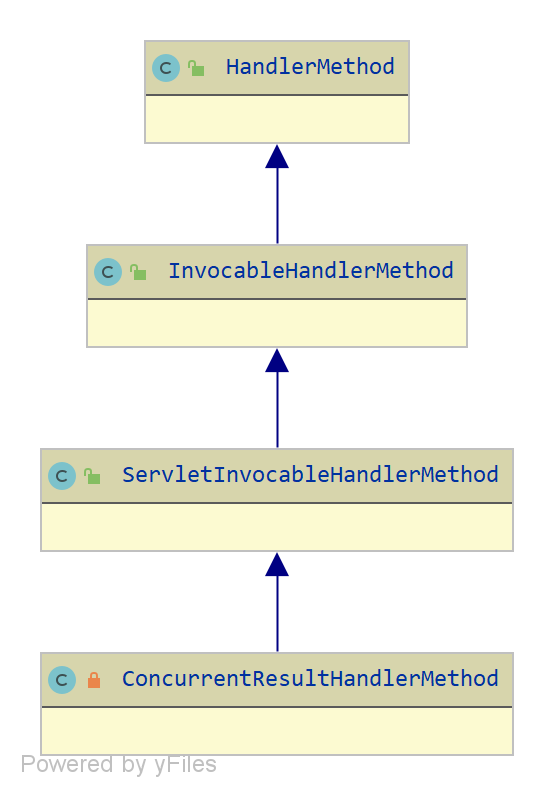
spring-web InvocableHandlerMethod 源码分析
说明 本文基于 jdk 8, spring-framework 5.2.x 编写。author JellyfishMIX - github / blog.jellyfishmix.comLICENSE GPL-2.0 类层次 HandlerMethod,处理器的方法的封装对象。HandlerMethod 只提供了处理器的方法的基本信息,不提供调用逻辑。 Invoca…...
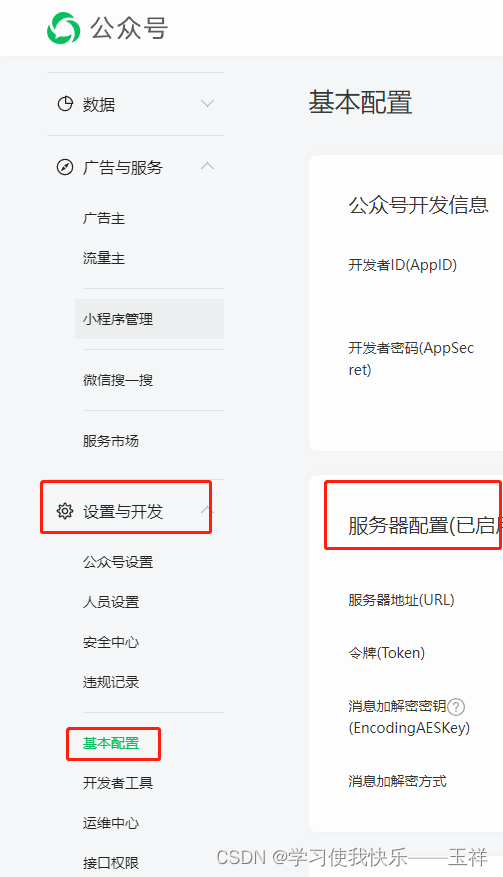
一分钟了解微信公众号服务器配置自动回复
1、建一个web服务工程 2、开放任意一个接口, 比如 /aaa/bbb/ccc 把接口路径配置在这里,ip为公网ip或域名,其他的参数默认,对入门选手没啥用 3、该接口允许get和post两种方式访问,接口需要对于访问方式编写两套逻辑…...

打印不同的图形-课后程序(JAVA基础案例教程-黑马程序员编著-第四章-课后作业)
【案例4-1】打印不同的图形 记得 关注,收藏,评论哦,作者将持续更新。。。。 【案例介绍】 案例描述 本案例要求编写一个程序,可以根据用户要求在控制台打印出不同的图形。例如,用户自定义半径的圆形和用户自定义边长的…...

14. QT_OPenGL中引入顶点着色器和片段着色器
1. 说明: 着色器是OPenGL中非常重要的一部分,在有了模型后,如果未给模型添加着色器,那么渲染效果会折扣很多。着色器中使用到的语言是GLSL(OPenGL Shader Language),可以通过这篇文章GLSL基本语法进行了解。 效果展示:…...
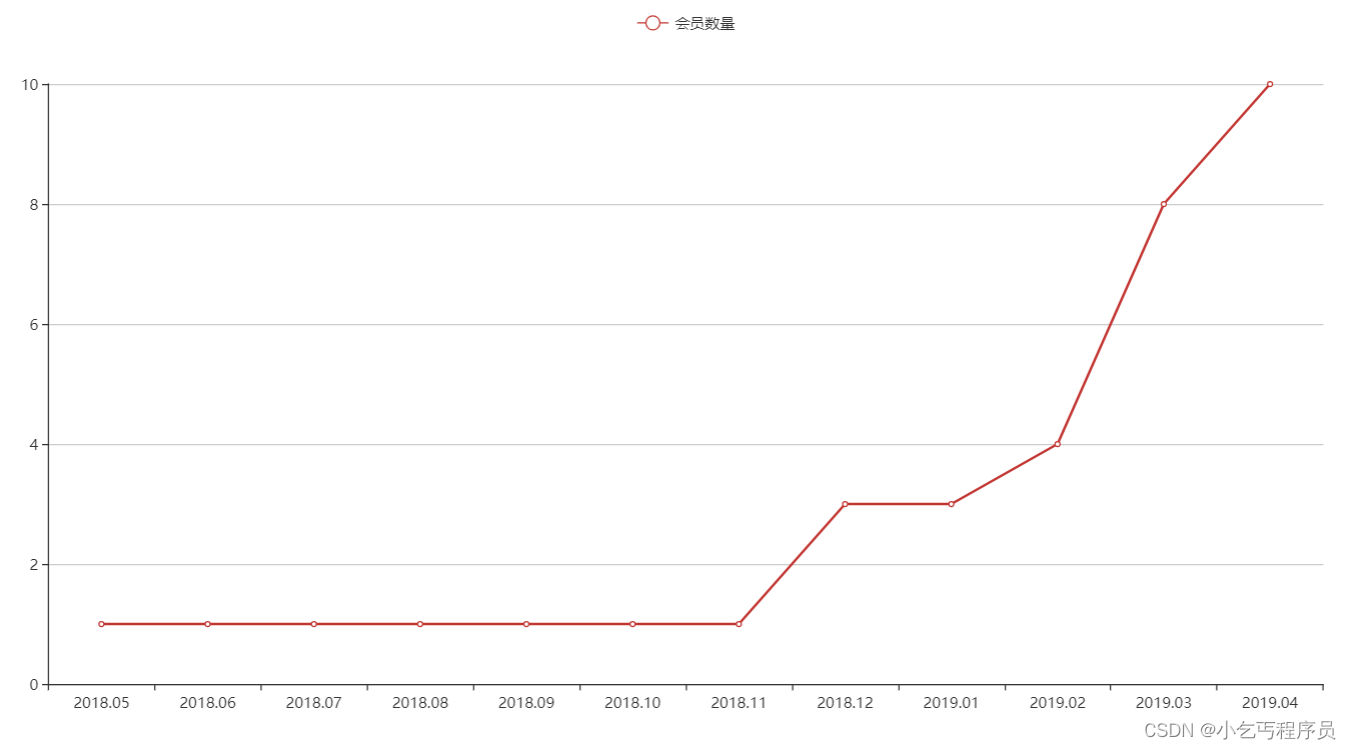
ecaozzz
2. 图形报表ECharts 2.1 ECharts简介 ECharts缩写来自Enterprise Charts,商业级数据图表,是百度的一个开源的使用JavaScript实现的数据可视化工具,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/…...
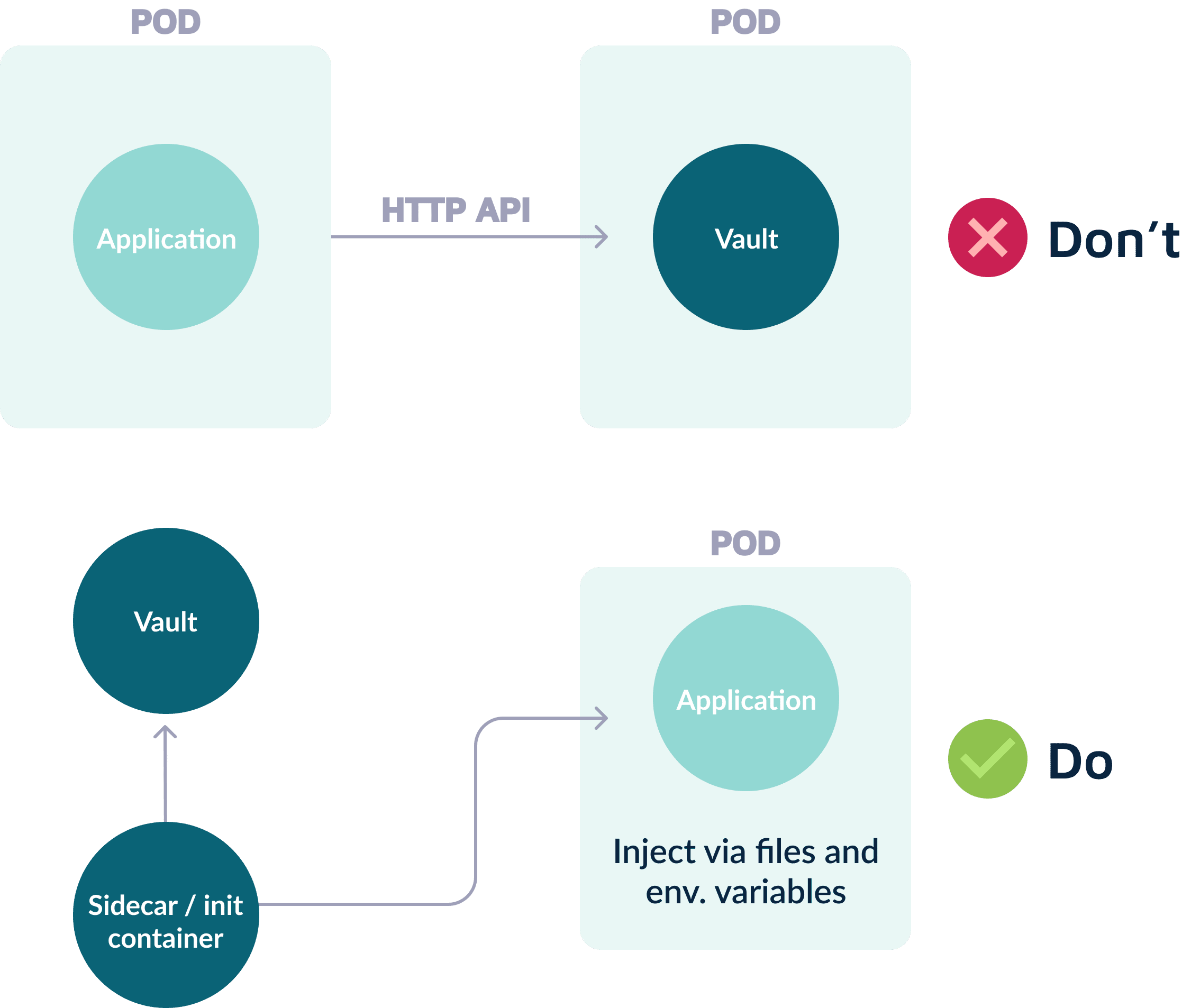
应用部署初探:6个保障安全的最佳实践
在之前的文章中,我们了解了应用部署的阶段以及常见的部署模式,包括微服务架构的应用应该如何部署等基本内容。本篇文章将介绍如何安全地部署应用程序。 安全是软件开发生命周期(SDLC)中的关键部分,同时也需要成为 S…...
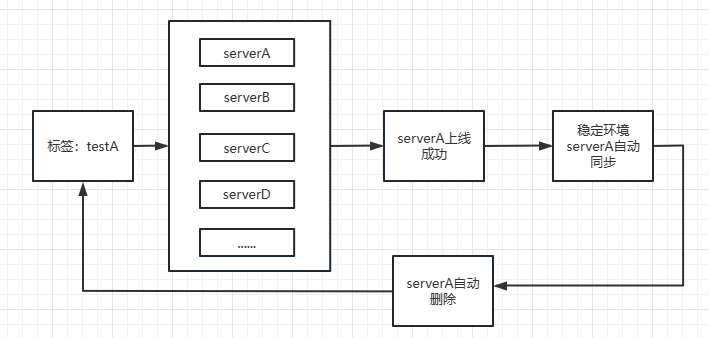
转转测试环境docker化实践
测试环境对于任何一个软件公司来讲,都是核心基础组件之一。转转的测试环境伴随着转转的发展也从单一的几套环境发展成现在的任意的docker动态环境docker稳定环境环境体系。期间环境系统不断的演进,去适应转转集群扩张、新业务的扩展,走了一些…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

js 设置3秒后执行
如何在JavaScript中延迟3秒执行操作 在JavaScript中,要设置一个操作在指定延迟后(例如3秒)执行,可以使用 setTimeout 函数。setTimeout 是JavaScript的核心计时器方法,它接受两个参数: 要执行的函数&…...

CppCon 2015 学习:REFLECTION TECHNIQUES IN C++
关于 Reflection(反射) 这个概念,总结一下: Reflection(反射)是什么? 反射是对类型的自我检查能力(Introspection) 可以查看类的成员变量、成员函数等信息。反射允许枚…...
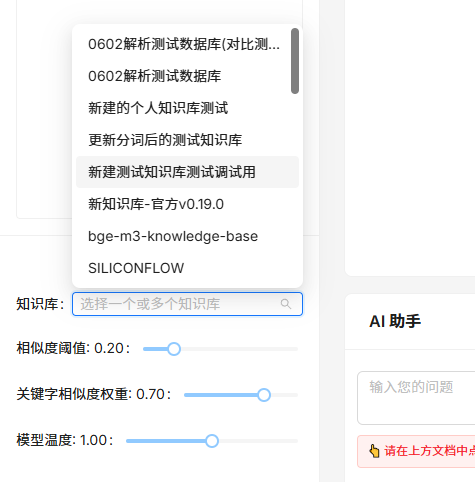
【Ragflow】26.RagflowPlus(v0.4.0):完善解析逻辑/文档撰写模式全新升级
概述 在历经半个月的间歇性开发后,RagflowPlus再次迎来一轮升级,正式发布v0.4.0。 开源地址:https://github.com/zstar1003/ragflow-plus 更新方法 下载仓库最新代码: git clone https://github.com/zstar1003/ragflow-plus.…...

【计算机网络】SDN
SDN这种新型网络体系结构的核心思想:把网络的控制层面与数据层面分离,而让控制层面利用软件来控制数据层面中的许多设备。 OpenFlow协议可以被看成是SDN体系结构中控制层面与数据层面之间的通信接口。 在SDN中取代传统路由器中转发表的是“流表”&…...