Hadoop入门学习笔记——三、使用HDFS文件系统
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
Hadoop入门学习笔记(汇总)
目录
- 三、使用HDFS文件系统
- 3.1. 使用命令操作HDFS文件系统
- 3.1.1. HDFS文件系统基本信息
- 3.1.2. HDFS文件系统的2套命令体系
- 3.1.3. 创建文件夹
- 3.1.4. 查看指定目录下的内容
- 3.1.5. 上传文件到HDFS指定目录下
- 3.1.6. 查看HDFS中文件的内容
- 3.1.7. 从HDFS下载文件到本地
- 3.1.8. 复制HDFS文件(在HDFS系统内复制)
- 3.1.9. 追加数据到HDFS文件中
- 3.1.10. 移动或重命名HDFS文件(在HDFS系统内移动)
- 3.1.11. 删除HDFS文件
- 3.1.12. 其他HDFS命令
- 3.2. HDFS Web浏览
- 3.3. HDFS系统权限
- 3.3.1. 修改HDFS文件权限
- 3.3.2. 修改HDFS文件所属用户和组
- 3.4. 使用Jetbrians产品插件——Big Data Tools操作HDFS
- 3.4.1. 安装Big Data Tools插件
- 3.4.2. 安装Hadoop并配置环境变量
- 3.4.3. 配置Big Data Tools插件
- 3.4.4. 使用Big Data Tools插件
- 3.4.5. 使用读取本地Hadoop配置文件的方式创建HDFS连接
- 3.5. 使用NFS网关功能将HDFS挂载到Windows系统(Windows系统必须为专业版,否则无法挂载)
- 3.5.1. 在HDFS端配置NFS
- 3.5.2. 验证NFS是否正常
- 3.5.3. 在Windows系统中挂载HDFS文件系统
- 3.6. 修改HDFS数据块的副本数量
- 3.6.1. HDFS副本块数量的配置
- 3.6.2. 指定某一个文件的HDFS副本块个数
- 3.6.3. 使用fsck命令检查文件的副本数量
- 3.6.4. block配置
- 3.7. NameNode元数据管理维护
- 3.8. HDFS系统数据读写流程
- 3.8.1. HDFS数据写入流程
- 3.8.2. HDFS数据读取流程
三、使用HDFS文件系统
3.1. 使用命令操作HDFS文件系统
3.1.1. HDFS文件系统基本信息
- HDFS和Linux系统一样,均是以
/作为根目录的组织形式; - 如何区分HDFS和Linux文件系统:
- Linux文件系统以
file://作为协议头,HDFS文件系统以hdfs://namenode:port作为协议头; - 例如,有路径
/usr/local/hello.txt,在Linux文件系统中表示为file:///usr/local/hello.txt,在HDFS文件系统中表示为hdfs://node1:8020/usr/local/hello.txt; - 但一般情况下,协议头是可以省略的,使用Linux命令时,会自动识别为
file://协议头,使用HDFS命令时,会自动识别为hdfs://namenode:port协议头; - 但如果需要再使用HDFS命令操作Linux文件时,需要明确使用
file://协议头。
- Linux文件系统以
3.1.2. HDFS文件系统的2套命令体系
老版本
用法:hadoop fs [generic options]
新版本
用法:hdfs dfs [generic options]
两套命令用法完全一致,效果完全一样,但某些特殊命令需要选择hadoop或hdfs命令。
3.1.3. 创建文件夹
用法:
hadoop fs -mkdir [-p] <path> ...
hdfs dfs -mkdir [-p] <path> ...
path为待创建的目录
-p 选项意思与Linux的mkdir -p一样,自动逐层创建对应的目录。
例如:
hadoop fs -mkdir -p file:///home/hadoop/test 在Linux系统下创建/home/hadoop/test文件夹;
hadoop fs -mkdir -p hdfs://node1:8020/itheima/bigdata 在HDFS中创建/itheima/bigdata文件夹;
hdfs dfs -mkdir -p /home/hadoop/itcast 在HDFS中创建/home/hadoop/itcast文件夹;
3.1.4. 查看指定目录下的内容
用法:
hadoop fs -ls [-h] [-R] [<path> ...]
hdfs dfs -ls [-h] [-R] [<path> ...]
path为指定的目录路径
-h 人性化显示size
-R 递归查看指定目录及其子目录。
例如:
hdfs dfs -ls / 查看HDFS 根目录下的内容
hadoop fs -ls / 查看HDFS 根目录下的内容,与上面等效
hdfs dfs -ls -R / 递归查看HDFS根目录下的内容
hdfs dfs -ls file:/// 查看当前这台Linux机器根目录下的内容
hdfs dfs -ls -h / 查看HDFS根目录下的内容,当文件大小大于1k之后,其大小会有单位,便于人的阅读;
3.1.5. 上传文件到HDFS指定目录下
用法:
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
-f 当目标文件已存在时,覆盖目标文件
-p 保留访问和修改时间,所有权和权限
localsrc 要上传的本地(Linux系统)文件的路径
dst 要保存在HDFS中的具体路径。
例如:
hadoop fs -put file:///home/hadoop/test.txt hdfs://node1:8020/ 将本地/home/hadoop/下的test.txt文件上传到HDFS的根目录下的完整写法;
hdfs dfs -put test2.txt / 将本地当前目录下的test2.txt文件上传到HDFS的根目录下;
hdfs dfs -put -f test2.txt / 将本地目录下的test2.txt文件上传到HDFS的根目录下,并强制覆盖原有的test2.txt文件;
3.1.6. 查看HDFS中文件的内容
用法:
hadoop fs -cat <src> ...
hdfs dfs -cat <src> ...
读取大文件时,可以使用管道符配合more
hadoop fs -cat <src> | more
hdfs dfs -cat <src> | more
例如:
hadoop fs -cat /test.txt 查看HDFS根目录下test.txt文件的内容
hdfs dfs -cat /test2.txt | more 查看HDFS根目录下的test2.txt文件的内容,可以翻页,适用于查看大文件
3.1.7. 从HDFS下载文件到本地
用法:
hadoop fs -get [-f] [-p] <src> ... <localdst>
hdfs dfs -get [-f] [-p] <src> ... <localdst>
-f 当目标文件已存在时,覆盖目标文件
-p 保留访问和修改时间,所有权和权限
src 要下载的HDFS文件路径
localdst 要保存在本地Linux系统中的路径。
例如:
hadoop fs -get /test.txt . 将HDFS根目录下的test.txt文件下载到本地Linux系统的当前目录下;
hadoop fs -get -f /test.txt . 将HDFS根目录下的test.txt文件下载到本地Linux系统的当前目录下,若本地已存在test.txt,则强制覆盖;
hdfs dfs -get /test2.txt . 将HDFS根目录下的test2.txt文件下载到本地的当前目录下;
3.1.8. 复制HDFS文件(在HDFS系统内复制)
用法:
hadoop fs -cp [-f] <src> ... <dst>
hdfs dfs -cp [-f] <src> ... <dst>
-f 若目标文件存在,则强制覆盖目标文件
src HDFS文件系统中被复制的文件路径
dst 要复制到的HDFS文件系统目标路径
例如:
hadoop fs -cp /test.txt /home/ 将HDFS根目录下的test.txt文件复制到HDFS文件系统/home/目录下
hadoop fs -cp /test.txt /home/abc.txt 将HDFS根目录下的test.txt文件复制到HDFS文件系统/home/目录下,并将其改名为abc.txt
3.1.9. 追加数据到HDFS文件中
用法:
hadoop fs -appendToFile <localsrc> ... <dst>
hdfs dfs -appendToFile <localsrc> ... <dst>
localsrc Linux系统的本地文件路径,要追加的内容放在这个文件里
dst HDFS文件系统中被追加的文件,如果文件不存在则创建该文件
在HDFS系统中想要修改文件,仅有两种方式:删除 或 追加
例如:
hadoop fs -appendToFile append.txt /test.txt 将Linux本地当前目录下的append.txt文件中的内容追加到HDFS系统根目录下test.txt文件中去
3.1.10. 移动或重命名HDFS文件(在HDFS系统内移动)
用法:
hadoop fs -mv <src> ... <dst>
hdfs dfs -mv <src> ... <dst>
src HDFS文件系统中的源文件
dst HDFS文件系统中的目标位置
例如:
hadoop fs -mv /test.txt /itheima 将HDFS系统根目录下的test.txt文件移动到HDFS系统/itheima/目录里
hdfs dfs -mv /test2.txt /itheima/abc.txt 将HDFS系统根目录下的test2.txt文件移动到HDFS系统/itheima/目录里,并将其改名为abc.txt
3.1.11. 删除HDFS文件
用法:
hadoop fs -rm [-r] [-skipTrash] URI [URI ...]
hdfs dfs -rm [-r] [-skipTrash] URI [URI ...]
-r 删除文件夹时需要此参数,删除文件时不用
-skipTrash 跳过回收站,直接删除(彻底删除)
回收站功能默认是关闭的,如果需要开启,需要修改core-site.xml配置文件。
例如:
hadoop fs -rm -r /home 删除HDFS系统中的/home文件夹
hdfs dfs -rm /itheima/test.txt 删除HDFS系统中/itheima目录下的test.txt文件
配置开启Hadoop的回收站
修改core-site.xml配置文件vim /export/server/hadoop/etc/hadoop/core-site.xml:
<property><!--回收站保留的时间,1440的单位是分钟,代表着1天,超过这个时间之后,删除的文件就彻底删除了--><name>fs.trash.interval</name><value>1440</value>
</property><property><!--指垃圾回收的检查间隔,应该是小于或者等于fs.trash.interval,120分钟即每2小时检查一次,检查时发现如果有文件的删除时间大于上面的1440,就从回收站里面删掉,也就是彻底删除了--><name>fs.trash.checkpoint.interval</name><value>120</value>
</property>
无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。即如果只是在node1节点配置了,那只有在node1节点执行删除命令才有用,在其他节点执行是没用的!!!
回收站默认位置在:/user/用户名(hadoop)/.Trash
删除HDFS系统内的文件hadoop fs -rm /itheima/abc.txt会看到有如下提示
[hadoop@node1 ~]$ hadoop fs -rm /itheima/abc.txt
2023-12-02 14:58:06,322 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/itheima/abc.txt' to trash at: hdfs://node1:8020/user/hadoop/.Trash/Current/itheima/abc.txt
可以看到,虽然输入的是rm命令,但实际上HDFS系统会将要删除的文件移动到hdfs://node1:8020/user/hadoop/.Trash/Current/目录下。
此时,可以使用 hadoop fs -ls -R /命令查看,当开启回收站后,HDFS系统会在根目录下默认创建/user/当前用户/Current的目录(当前用户为hadoop)

当然,也可以通过参数-skipTrash实现彻底删除,不让被删除的文件进入回收站
hadoop fs -rm -r -skipTrash /itheima 彻底删除(不进入回收站)HDFS根目录下的itheima文件夹,此命令执行效果如下:
[hadoop@node1 ~]$ hadoop fs -rm -r -skipTrash /itheima
Deleted /itheima
可以看到,和不开回收站时,执行rm命令的效果一样。
3.1.12. 其他HDFS命令
官方文档:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html

3.2. HDFS Web浏览
除了上述的命令方式外,还可以通过HDFS NameNode节点的Web页面操作文件系统,入口在http://node1:9870/中

在Web页面中可以查看,但是没法操作文件,因为HDFS系统的权限是给hadoop用户的,但是Web页面默认情况下其实是个匿名用户(dr.who)

当然,也可以让Web页面拥有权限,需要修改core-site.xml配置文件,增加如下配置:
<property><name>hadoop.http.staticuser.user</name><value>hadoop</value>
</property>
将Web页面的权限设置成hadoop用户。
但是,不推荐这样做:
- HDFS WEBUI,只读权限挺好的,简单浏览即可
- 如果给与高权限,会有很大的安全问题,造成数据泄露或丢失
3.3. HDFS系统权限
HDFS系统有自己独立的权限体系,但其权限类型与Linux一致,都是按照读(r)、写(w)、可执行(x)进行授权,权限分为三组,从左到右依次是所有者的权限、所有组的权限、其他用户权限。通过hadoop fs -ls或hdfs dfs -ls命令可以查看到HDFS系统内各文件和文件夹的权限。
但与Linux不同的是,在Linux系统中超级用户是root,但在HDFS系统中,超级用户是启动namenode的用户(本示例中就是hadoop用户),如果在HDFS系统中的文件时遇到Permission denied等权限不足的报错提醒时,首先要检查的就是当前用户是否为启动namenode的用户。
3.3.1. 修改HDFS文件权限
用法:
hadoop fs -chmod [-R] 777 <path>
hdfs dfs -chmod [-R] 777 <path>
例如:
hadoop fs -chmod 777 /test3.txt 将HDFS根目录下的test3.txt文件的权限修改成所有人可读、可写、可执行
[hadoop@node1 ~]$ hadoop fs -chmod 777 /test3.txt
[hadoop@node1 ~]$ hdfs dfs -ls /test3.txt
-rwxrwxrwx 3 hadoop supergroup 268037352 2023-12-05 10:48 /test3.txt
3.3.2. 修改HDFS文件所属用户和组
用法:
hadoop fs -chown [-R] hadoop:supergroup <path>
hdfs dfs -chown [-R] hadoop:supergroup <path>
例如:
hadoop fs -chown root:supergroup /test.txt 将HDFS根目录下的test.txt文件的所有者修改为root用户,所有组为supergroup。
[hadoop@node1 ~]$ hadoop fs -chown root:supergroup /test.txt
[hadoop@node1 ~]$ hdfs dfs -ls /test.txt
-rw-r--r-- 3 root supergroup 44 2023-12-02 15:11 /test.txt
3.4. 使用Jetbrians产品插件——Big Data Tools操作HDFS
3.4.1. 安装Big Data Tools插件
在任意的Jetbrians产品(如IntelliJ IDEA、PyCharm等)中,打开Settings-Plugins,搜索、安装Big Data Tools;
安装完成后,根据提示,重启IDE即可;

重启IDE后,可在IDE的右侧看到Big Data Tools的工作Tab。
3.4.2. 安装Hadoop并配置环境变量
1、下载Hadoop(之前其实下载):https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
2、下载后,将其解压到本地(Windows系统)的任意路径(注意:直接解压到对应的路径,不要先解压再复制或移动,因为其里面部分文件夹的路径名长度超过了Windows系统的限制,如果复制或移动的话,可能会导致部分文件夹复制失败),如:D:\Software\Work\hadoop-3.3.4;
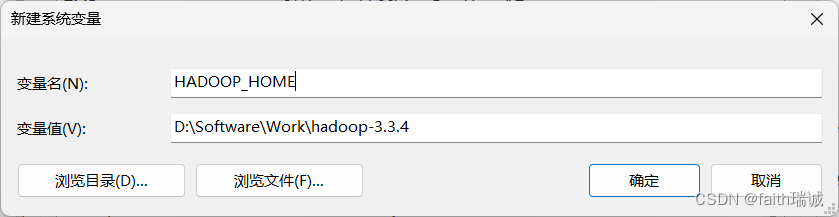
3、在“此电脑-属性-高级系统设置-环境变量”中,增加HADOOP_HOME环境变量,其值为D:\Software\Work\hadoop-3.3.4;
4、下载
hadoop.dll:https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/hadoop.dll
winutils.exe:https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/winutils.exe
5、将hadoop.dll和winutils.exe放入$HADOOP_HOME/bin目录中;
3.4.3. 配置Big Data Tools插件
1、打开Big Data Tools插件,新建一个HDFS链接;
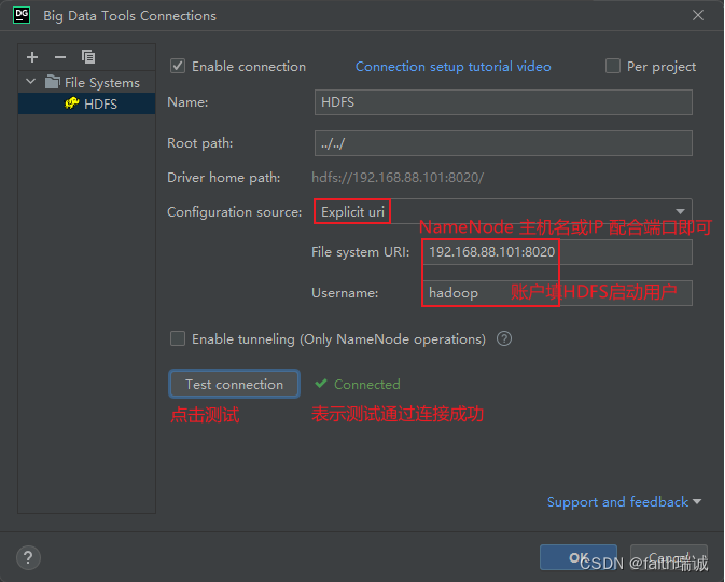
2、Authentication Type选择为Explicit uri,File System URI修改为namenode的地址,Username修改为集群中启动HDFS的用户名,然后点击Test connection按钮,测试连通性,若显示Connected,则代表配置正确(前提是HDFS集群已启动);
若在测试连接时提示HADOOP_HOME环境变量未配置,但又确实已经配置了的情况下,可以尝试重启Windows系统解决。
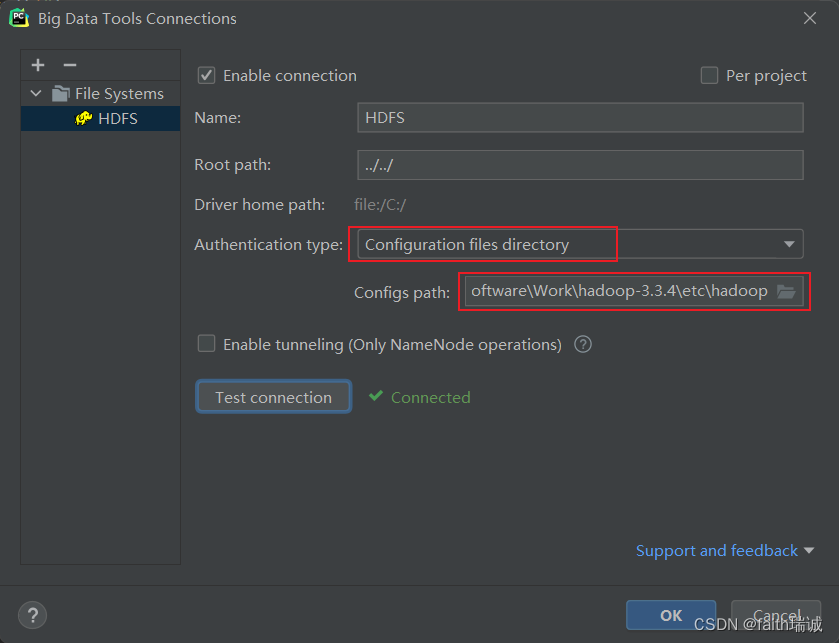 3、创建完毕后,可以看到与命令行一致的HDFS系统目录结构。
3、创建完毕后,可以看到与命令行一致的HDFS系统目录结构。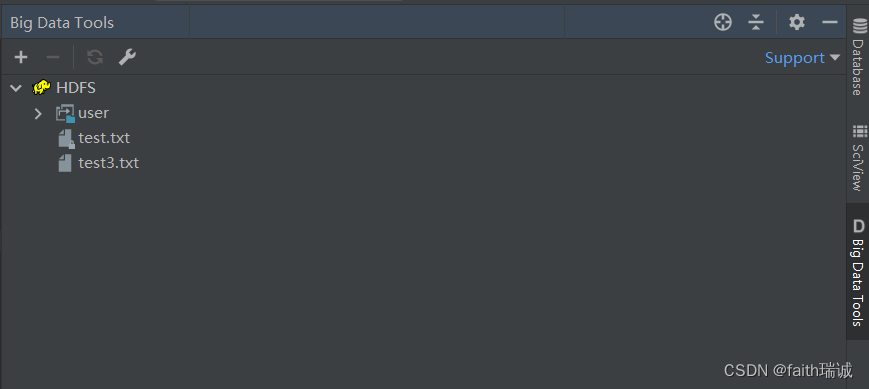
3.4.4. 使用Big Data Tools插件
1、可以在HDFS上右键,通过New Directory…创建新目录;
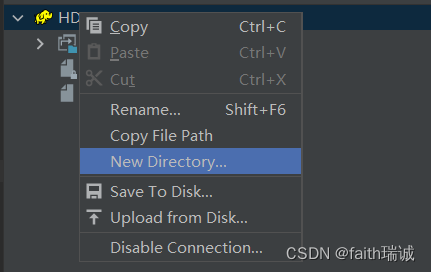
2、可以在任意文件夹上右键,通过Upload from Disk…将本地的文件或文件夹上传至HDFS;
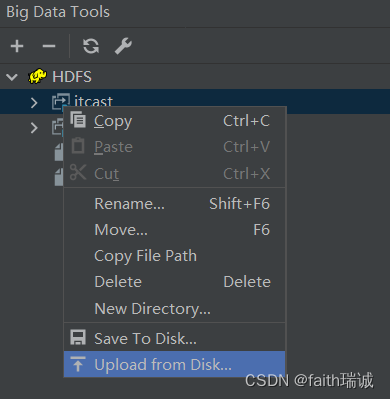
3、可以鼠标左键双击HDFS系统内的文件,直接打开HDFS系统里的文件进行查看;
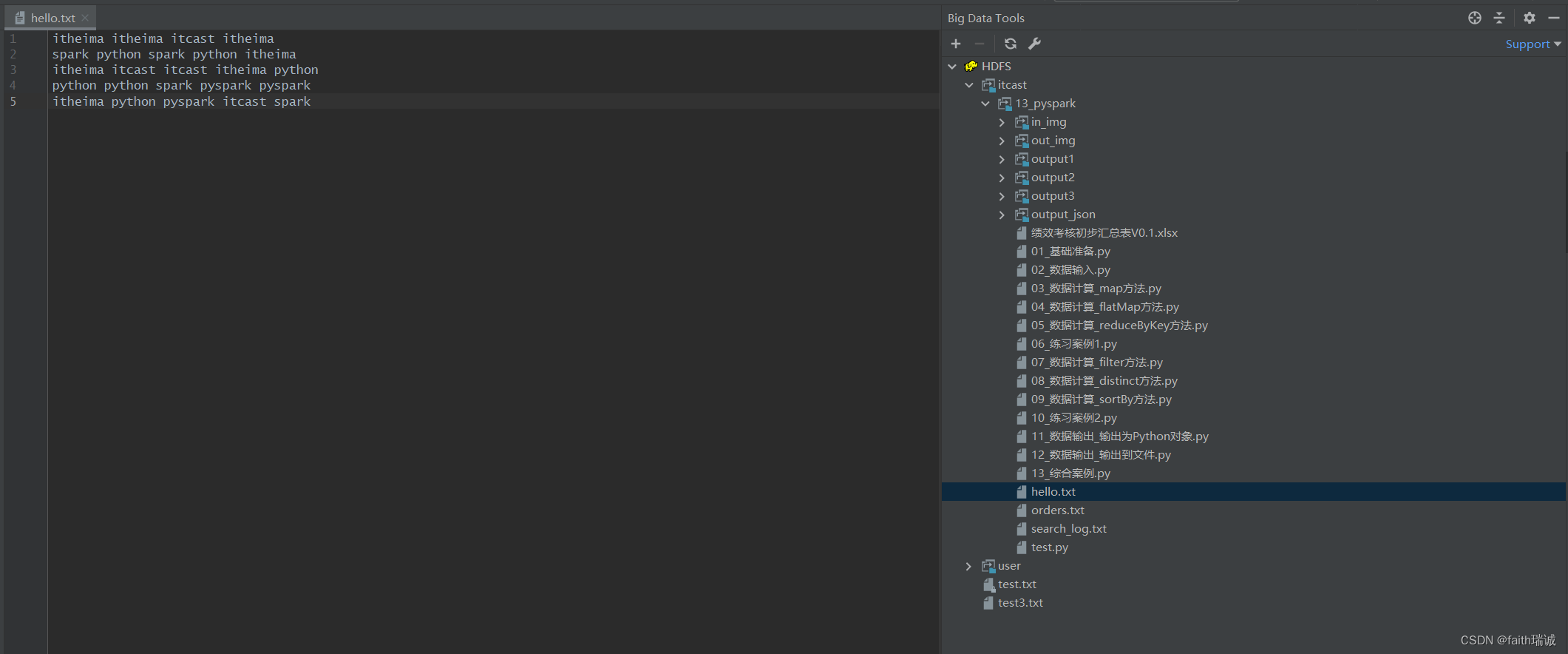
4、可以在文件或文件夹上右键,选择Save To Disk… 将HDFS系统中的文件下载到本地;
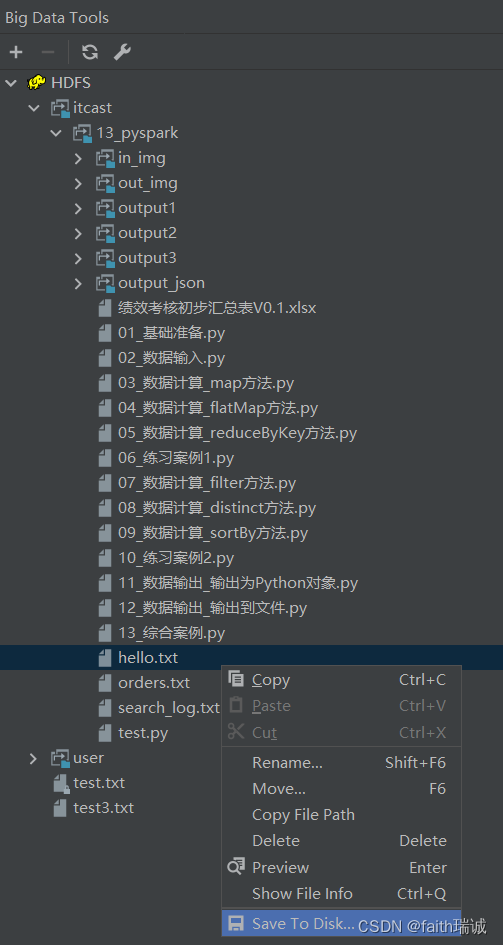
5、还有其他一些删除、复制、重命名等功能,均可通过该插件进行图形化界面操作。
3.4.5. 使用读取本地Hadoop配置文件的方式创建HDFS连接
1、除了上述使用namenode的IP和端口号的方式,也可以使用读取本地的Hadoop配置创建HDFS连接;
2、前序步骤已将Hadoop安装包解压在了D:\Software\Work\hadoop-3.3.4目录,此时,需要从node1虚拟机中,将虚拟机的Hadoop的所有配置文件(即/export/server/hadoop-3.3.4/etc/hadoop目录下所有的配置文件)打包下载到本地,并用虚拟机上的Hadoop配置文件覆盖本地的所有配置文件;
3、使用虚拟机中的配置文件覆盖本地的配置文件后,需要注意配置文件中的node1在本地的hosts文件中是否配置正确的IP地址,或者直接将配置文件中的节点名称改成节点对应IP地址也可以;
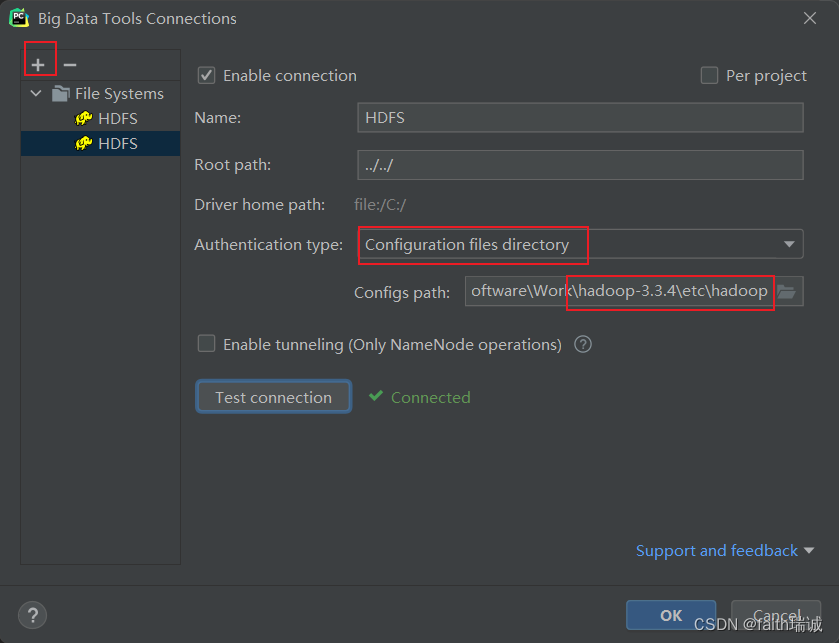
4、在Big Data Tools插件中进行配置,选择HADOOP_HOME/etc/hadoop路径即可;
3.5. 使用NFS网关功能将HDFS挂载到Windows系统(Windows系统必须为专业版,否则无法挂载)
3.5.1. 在HDFS端配置NFS
1、在node1虚拟机中,使用命令cd /export/server/hadoop-3.3.4/etc/hadoop进入hadoop配置文件夹;
2、使用vim core-site.xml命令打开配置文件,并在其中追加如下内容:
<property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property>
其中:
hadoop.proxyuser.hadoop.groups配置项的值为 *,表示允许hadoop用户代理任何其他用户组;
hadoop.proxyuser.hadoop.hosts配置型的值为 *,表示允许代理任意服务器的请求。
3、使用vim hdfs-site.xml命令打开配置文件,并在其中追加如下内容:
<property><name>nfs.superuser</name><value>hadoop</value></property><property><name>nfs.dump.dir</name><value>/tmp/.hdfs-nfs</value></property><property><name>nfs.exports.allowed.hosts</name><value>192.168.88.1 rw</value></property>
其中:
nfs.superuser配置项的值为hadoop,表示NFS操作HDFS系统时,所使用的用户为hadoop(即超级用户);
nfs.dump.dir配置项的值为/tmp/.hdfs-nfs,表示NFS接收数据上传时使用的临时目录的路径;
nfs.exports.allowed.hosts配置项的值为192.168.88.1 rw,表示NFS允许连接的客户端的IP和权限,rw表示具有读和写的权限,IP部分也可以使用*表示所有IP均可连接(这里的192.168.88.1地址是本地电脑在虚拟机网络中的IP地址,如果这里不是虚拟机,而是真实服务器,则需要使用本机对应的公网IP或局域网IP),同时如果有多个电脑需要连接,也可以写成192.168.88.1 rw;10.0.3.5 rw;192.168.88.113 rw;的方式配置允许连接的客户端IP和权限;
4、将上述修改的两个配置文件分发到node2和node3节点:
[hadoop@node1 hadoop]$ scp core-site.xml hdfs-site.xml node2:`pwd`/
core-site.xml 100% 1334 1.7MB/s 00:00
hdfs-site.xml 100% 1617 1.9MB/s 00:00
[hadoop@node1 hadoop]$ scp core-site.xml hdfs-site.xml node3:`pwd`/
core-site.xml 100% 1334 1.6MB/s 00:00
hdfs-site.xml 100% 1617 2.0MB/s 00:00
5、使用stop-dfs.sh停止HDFS集群(必须以hadoop用户身份);
6、停止虚拟机系统的NFS相关进程(必须以root用户身份)
# 切换成root用户
su root
# 关闭CentOS系统的nfs服务
systemctl stop nfs
# 关闭NFS服务的开机自启动,后面用HDFS自带的nfs服务
systemctl disable nfs
# 卸载rpcbind服务,后面使用HDFS自带的rpcbind服务
yum remove -y rpcbind
7、以root用户身份,使用hdfs --daemon start portmap命令启动HDFS自带的rpcbind功能,可通过jps命令查看当前进程情况,可以看到已经有一个Portmap进程启动了;

8、以hadoop用户身份启动HDFS自带的NFS服务:
# 切换为hadoop用户
su - hadoop
# 启动HDFS自带的NFS服务
hdfs --daemon start nfs3
9、使用start-dfs.sh命令启动HDFS集群
3.5.2. 验证NFS是否正常
以下操作需要在node2或node3执行,因为node1刚才已经卸载了系统自带的rpcbind服务,缺少了必要的2个命令。
1、执行rpcinfo -p node1命令,如果看到有mountd和nfs出现,则代表正常情况;
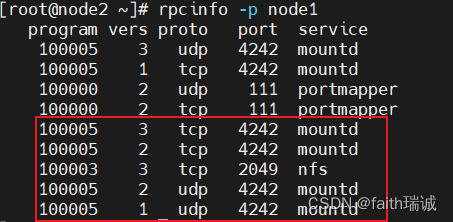
2、执行showmount -e node1命令,看到/ 192.168.88.1,表示允许192.168.88.1这个IP连接到HDFS的根目录(/);

3.5.3. 在Windows系统中挂载HDFS文件系统
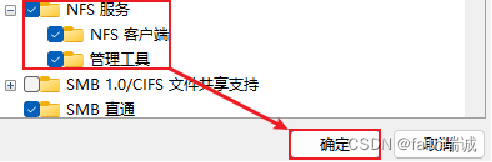
1、开启Windows的NFS功能:在控制面板-程序-启用或关闭Windows功能中,找到NFS服务,勾选上,点击确定,进行开启(此操作需要操作系统为专业版,若是家庭版则无法开启NFS功能);
2、在Windows命令提示符(CMD)内输入:net use X: \\192.168.88.101\!

上述命令中,X表示将HDFS文件系统挂在成本地的X盘,这里可以改成任何没有被占用的盘符;
3、上述命令执行成功后,打开资源管理器,可以看到已经挂载好的X盘,双击即可打开查看HDFS文件系统中的文件和文件夹,也可以进行文件的上传、下载 、复制、移动、查看文件内容等,但是无法修改文件内容;
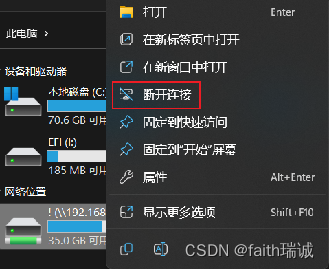
4、在X盘上右键选择“断开连接”,可以卸载HDFS系统(相当于umount命令)。
3.6. 修改HDFS数据块的副本数量
3.6.1. HDFS副本块数量的配置
1、如果没有单独配置,在HDFS中一个数据块默认大小为256MB,一个数据块默认的副本数量为3;
2、可以通过在hdfs-site.xml文件中修改如下配置,修改HDFS数据块的默认副本数量:
<property><name>dfs.replication</name><value>3</value></property>
dfs.replication属性用于配置数据块的默认副本数量,该配置默认为3。如果需要修改这个属性,需要在每一台服务器的hdfs-site.xml文件中进行修改;
3、修改完成后,需要重启集群,配置才能生效。
3.6.2. 指定某一个文件的HDFS副本块个数
1、除了配置文件外,可以在上传的时候,为当前要上传的文件临时指定副本块数量,该指定仅对当前要上传的文件起作用,命令如下:
# 将本地的test.txt文件上传到HDFS系统的/tmp/文件夹下,并设置test.txt文件上传后的数据块副本数量为2
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
2、对已经存在于HDFS系统中的文件,修改hdfs-site.xml文件中的dfs.replication属性时,不会导致这些文件的副本数量变化,但可以通过命令来实现:
# 将HDFS系统中的path路径所示的文件或文件夹的副本数量修改为2(也可以改成别的数字)
hadoop fs -setrep [-R] 2 path
-R 表示对指定路径的子目录及其下属文件也生效
例如:
hadoop fs -setrep 1 /test_3.txt
3.6.3. 使用fsck命令检查文件的副本数量
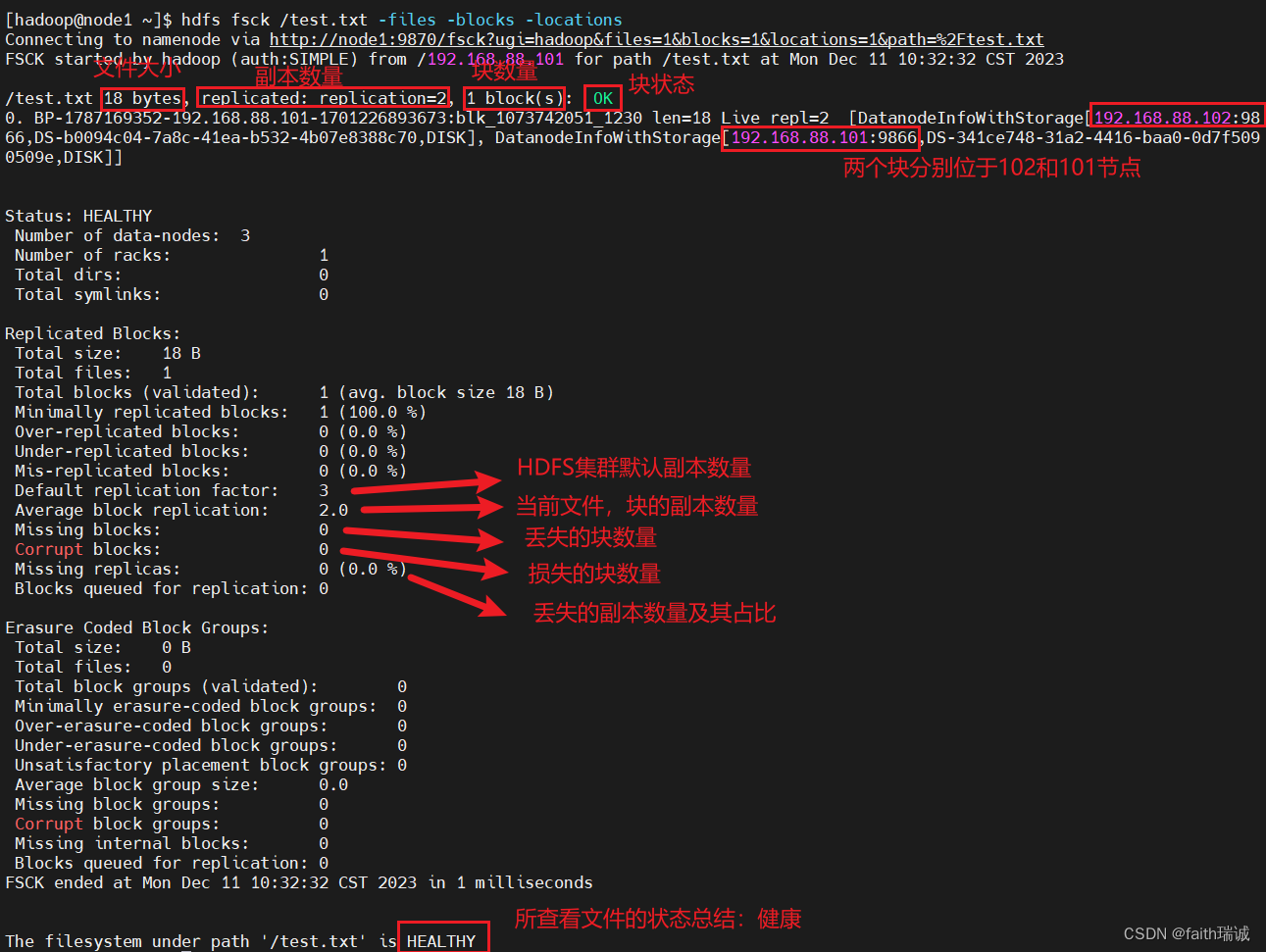
我们可以使用fsck命令检查文件的副本数量,用法:
hdfs fsck path [-files [-blocks [-locations]]]
fsck可以检查指定路径是否正常;
-files 可以列出路径内的文件状态
-files -blocks 输出文件块报告(由几个块,由几个副本)
-files -blocks -locations 可以输出每一个block的详情
用法:
hdfs fsck /test.txt -files -blocks -locations
命令执行结果如下:
3.6.4. block配置
对于块(block),HDFS系统默认设置为256MB一个块,也就是1GB文件会被分为4个block存储。块大小也可以通过在hdfs-site.xml文件中修改如下配置进行修改:
<property><name>dfs.blocksize</name><value>268435456</value></property>
dfs.blocksize配置项的单位是byte,上面写的268435456即是256MB(1MB=1024KB,1KB=1024byte)
3.7. NameNode元数据管理维护
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
- 每次对HDFS系统的操作,均被edits文件记录;
- edits达到大小上限后,会开启新的edits文件进行记录;
- 定期进行edits的合并操作:
- 如果当前没有fsimage文件,则将全部的edits合并为第一个fsimage文件;
- 如果当前已经存在fsimage文件,将全部的edits和已经存在的fsimage进行合并,形成新的fsimage文件;
- 重复上述1-3步骤。
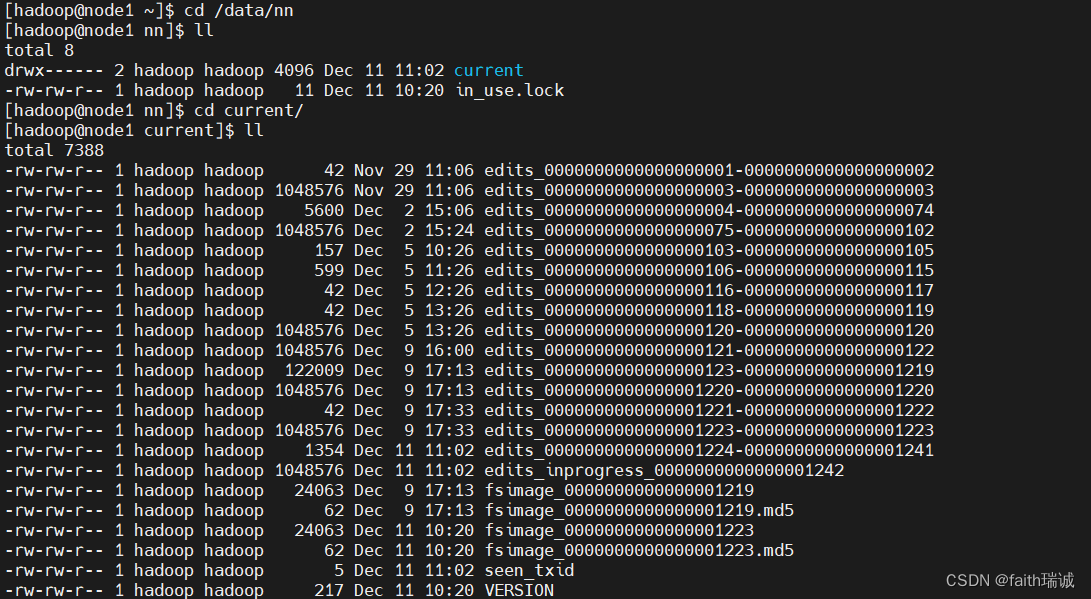
在前面介绍Hadoop配置时,在hdfs-site.xml配置文件中,配置了dfs.namenode.name.dir属性,值为/data/nn,通过查看node1服务器的/data/nn下的current目录,可以看到当前集群的edits文件和fsimage文件:
元数据合并的控制参数
对于元数据的合并,是一个定时执行的过程,基于hdfs-site.xml配置文件中的:
- dfs.namenode.checkpoint.period属性配置,默认为3600(单位:秒),即1小时执行一次合并;
- dfs.namenode.checkpoint.txns属性配置,默认1000000(单位:次),即100万次事务执行一次合并;
上述两个条件,只要有一个达到,就触发一次合并动作。
检查是否达到条件,默认60秒回检查一次,若想修改这个检查间隔,可以通过修改: - dfs.namenode.checkpoint.check.period属性配置,默认60(单位:秒)
元数据合并的工作是由SecondaryNameNode进程负责,NameNode只负责记录流水账(edits文件):
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage文件),然后合并完成并提供给NameNode使用。
所以在启动HDFS集群时,必须要启动SecondaryNameNode,否则就没有程序去合并edits,导致的结果就是随着HDFS的运行,查询效率会越来越低。
3.8. HDFS系统数据读写流程
3.8.1. HDFS数据写入流程
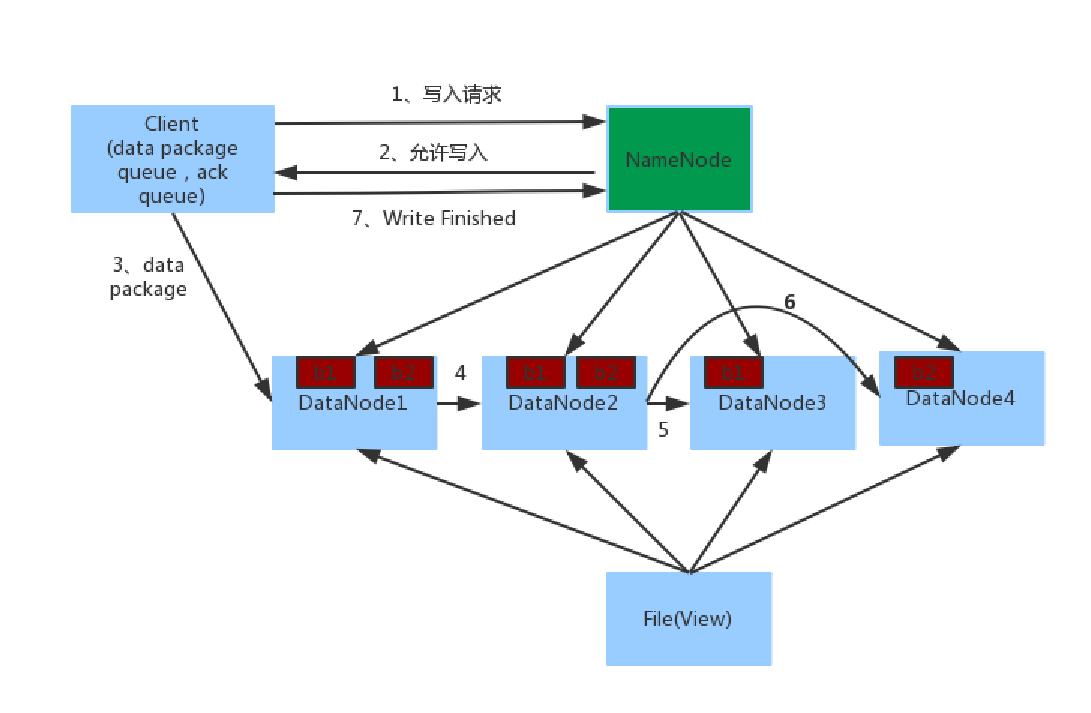
- 客户端向NameNode发起请求;
- NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址;
- 客户端向指定的DataNode发送数据包;
- 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode;
- 如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode4;
- 写入完成客户端通知NameNode,NameNode做元数据记录工作。
关键信息点:
- NameNode不负责数据写入,只负责元数据记录和权限审批;
- 客户端直接向1台DataNode写数据,这个DataNode一般是 == 离客户端最近(网络距离) == 的那一个;
- 数据块副本的复制工作,由DataNode之间自行完成(构建一个PipLine,按顺序复制分发,如图1给2, 2给3和4)。
3.8.2. HDFS数据读取流程
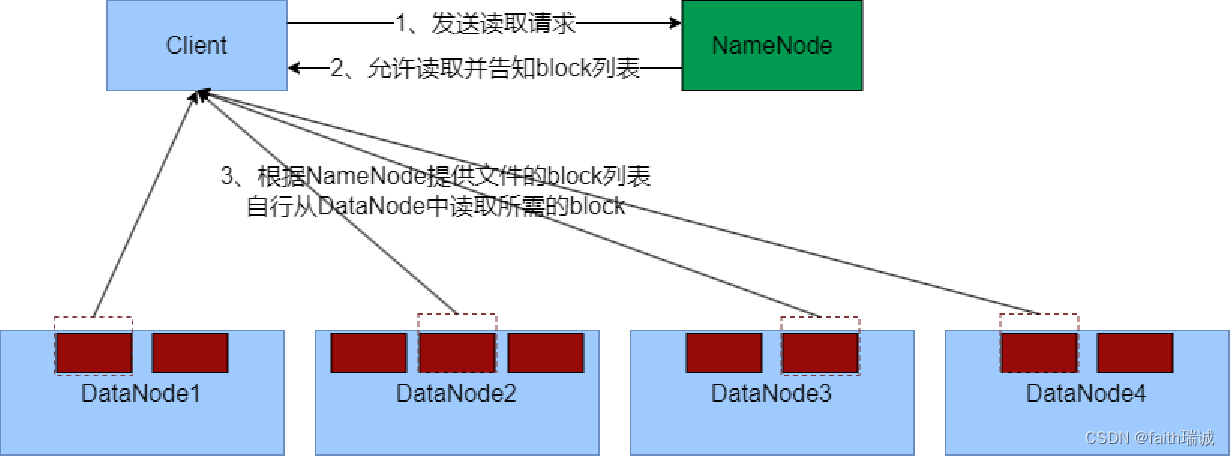
- 客户端向NameNode申请读取某文件;
- NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表;
- 客户端拿到block列表后自行寻找DataNode读取即可。
关键信息点:
- 数据同样不通过NameNode提供;
- NameNode提供的block列表,会基于网络距离计算尽量提供离客户端最近的,这是因为1个block有3份,会尽量找离客户端最近的那一份让其读取。
相关文章:
Hadoop入门学习笔记——三、使用HDFS文件系统
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 Hadoop入门学习笔记(汇总) 目录 三、使用HDFS文件系统3.1. 使用命令操作HDFS文件系统3.1.…...
JavaWeb—html, css, javascript, dom,xml, tomcatservlet
文章目录 快捷键HTML**常用特殊字符替代:****标题****超链接标签****无序列表、有序列表****无序列表**:ul/li 基本语法**有序列表ol/li:****图像标签(img)**** 表格(table)标签****表格标签-跨行跨列表格****form(表单)标签介绍****表单form提交注意事项**div 标签p 标签sp…...
LangChain 31 模块复用Prompt templates 提示词模板
LangChain系列文章 LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索I…...
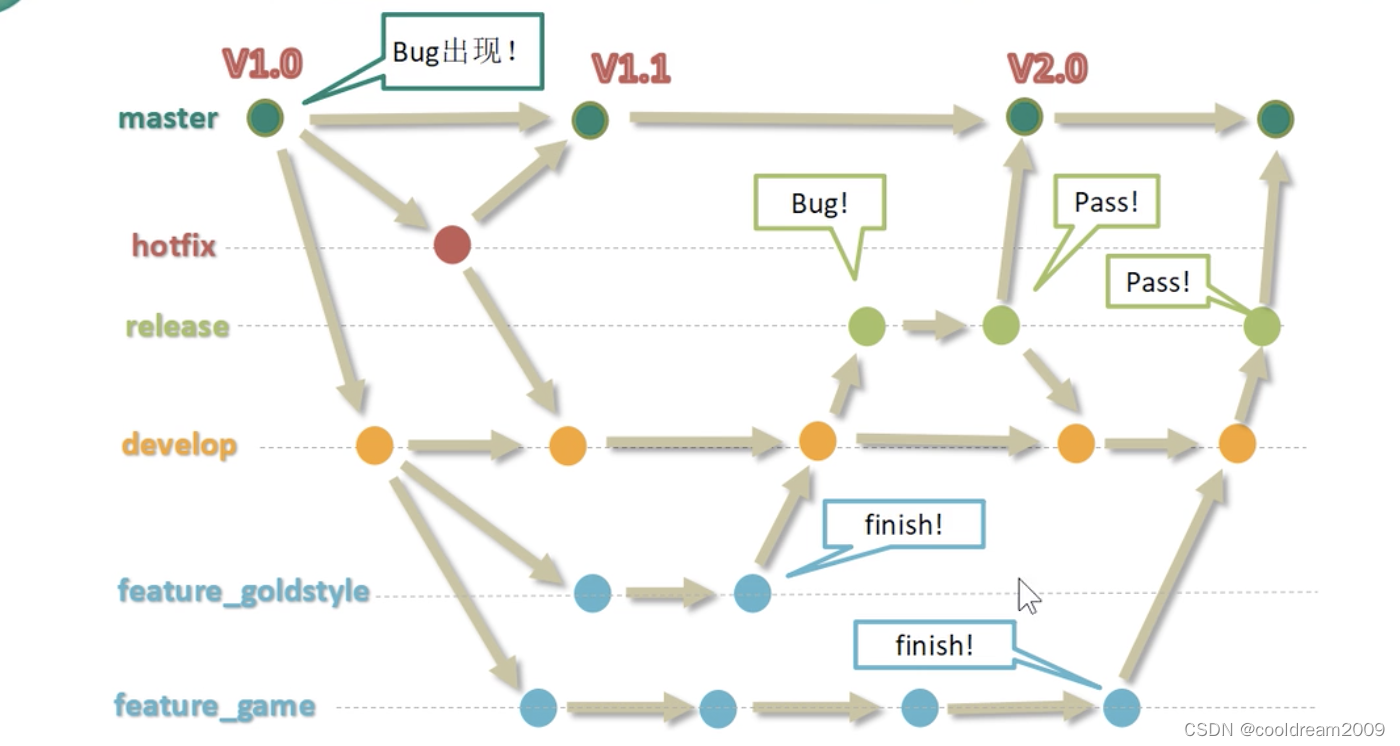
深入理解 Git 分支管理:提升团队协作与开发效率
目录 前言1 什么是分支2 分支的好处2.1 并行开发的支持2.2 独立性与隔离性2.3 灵活的版本控制2.4 提高安全性和代码质量2.5 项目历史的清晰记录 3 Git 分支操作命令3.1 git branch -v3.2 git branch 分支名称3.3 git checkout 分支名称3.4 git merge 分支名称3.5 git rebase 分…...

WPF StackPanel
StackPanel是一个控件容器,它按照一个方向(水平或垂直)堆叠子元素,使得它们沿一个轴线对齐。你可以在StackPanel中放置其他控件,如按钮、标签、文本框、图片等等。这些控件的排列方式由StackPanel按照指定的方向自动确…...
由正规表达式构造DFA,以及DFA的相关化简
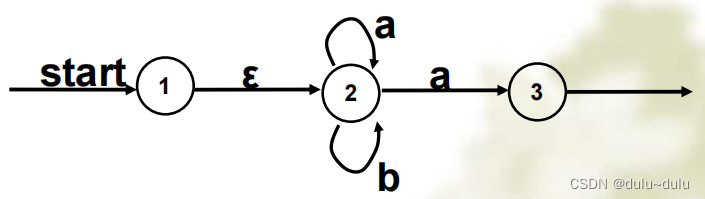
目录 1.由正规式到DFA 首先讲如何从正规式到NFA 如何从NFA到DFA 2.DFA的化简 3.DFA和NFA的区别 1.由正规式到DFA 正规式--->NFA---->DFA 首先讲如何从正规式到NFA 转换规则: 例题1:这里圆圈里面的命名是随意的,只要能区别开就可以了 如何…...
:Adaboost)
模式识别与机器学习(九):Adaboost
1.原理 AdaBoost是Adaptive Boosting(自适应增强)的缩写,它的自适应在于:被前一个基本分类器误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在…...
【JAVA】分布式链路追踪技术概论
目录 1.概述 2.基于日志的实现 2.1.实现思想 2.2.sleuth 2.2.可视化 3.基于agent的实现 4.联系作者 1.概述 当采用分布式架构后,一次请求会在多个服务之间流转,组成单次调用链的服务往往都分散在不同的服务器上。这就会带来一个问题:…...
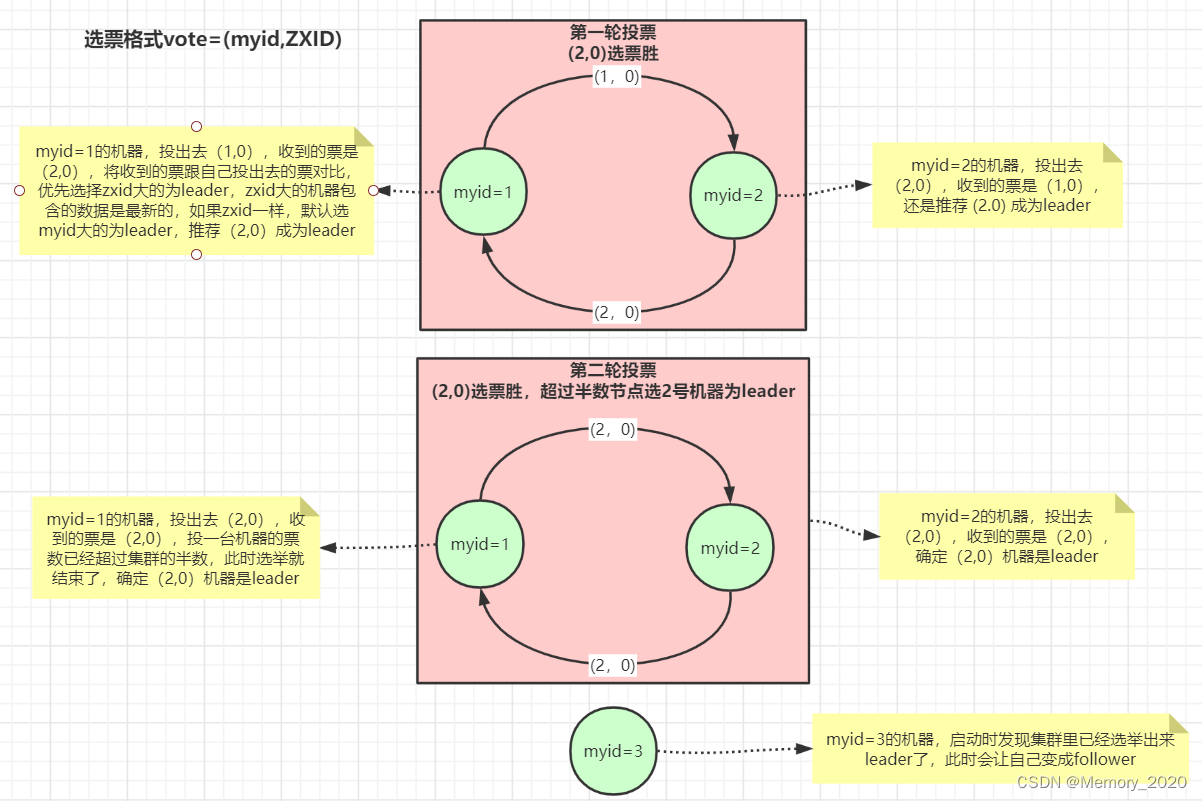
ZooKeeper 使用介绍和原理详解
目录 1. 介绍 重要性 应用场景 2. ZooKeeper 架构 服务角色 数据模型 工作原理 3. 安装和配置 下载 ZooKeeper 安装和配置 启动 ZooKeeper 验证和管理 停止和关闭 4. ZooKeeper 数据模型 数据结构和层次命名空间: 节点类型和 Watcher 机制ÿ…...
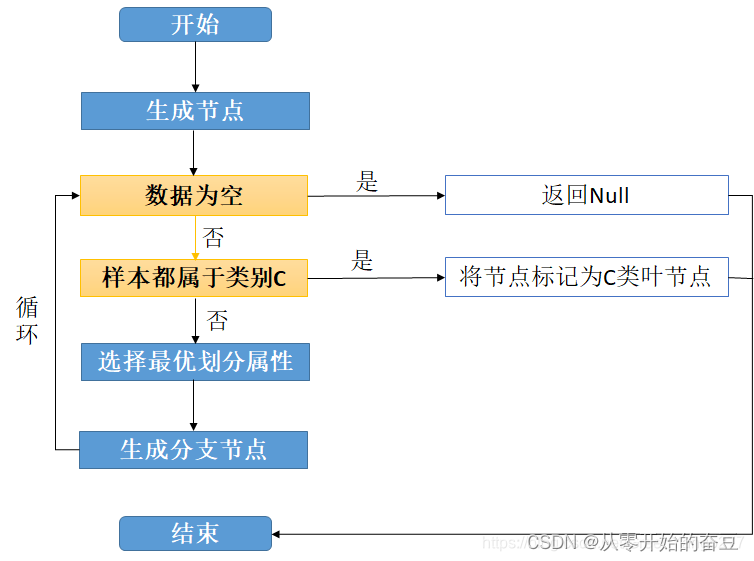
模式识别与机器学习(八):决策树
1.原理 决策树(Decision Tree),它是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知数据,通过某种技术手段将它们转化成可以预测未知数据的树状模…...
Pinely Round 3 (Div. 1 + Div. 2)(A~D)(有意思的题)
A - Distinct Buttons 题意: 思路:模拟从(0,0)到每个位置需要哪些操作,如果总共需要4种操作就输出NO。 // Problem: A. Distinct Buttons // Contest: Codeforces - Pinely Round 3 (Div. 1 Div. 2) // URL: https…...

在Linux下探索MinIO存储服务如何远程上传文件
🌈个人主页:聆风吟 🔥系列专栏:网络奇遇记、Cpolar杂谈 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. 创建Buckets和Access Keys二. Linux 安装Cpolar三. 创建连接MinIO服务公网地…...

持续集成交付CICD:Linux 部署 Jira 9.12.1
目录 一、实验 1.环境 2.K8S master节点部署Jira 3.Jira 初始化设置 4.Jira 使用 一、实验 1.环境 (1)主机 表1 主机 主机架构版本IP备注master1K8S master节点1.20.6192.168.204.180 jenkins slave (从节点) jira9.12.1…...

Linux命令-查看内存、GC情况及jmap 用法
查看进程占用内存、CPU使用情况 1、查看进程 #jps 查看所有java进程 #top 查看cpu占用高进程 输入m :根据内存排序 topMem: 16333644k total, 9472968k used, 6860676k free, 165616k buffers Swap: 0k total, 0k used, 0k free, 6…...

nginx安装letsencrypt证书
1.安装推荐安装letsencrypt证书的客户端工具 官方推荐通过cerbot客户端安装letsencrypt 官方推荐使用snap客户端安装cerbot客户端 apt install snapd snap install --classic certbot 建立certbot软链接:ln -s /snap/bin/certbot /usr/bin/certbot 2.开始安装letse…...
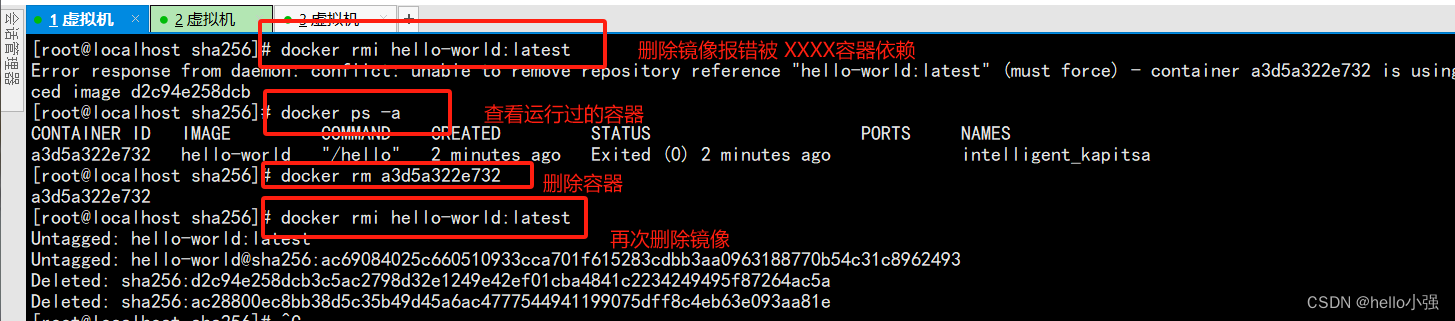
docker笔记1-安装与基础命令
docker的用途: 可以把应用程序代码及运行依赖环境打包成镜像,作为交付介质,在各种环境部署。可以将镜像(image)启动成容器(container),并提供多容器的生命周期进行管理(…...
VSCode软件与SCL编程
原创 NingChao NCLib 博途工控人平时在哪里技术交流博途工控人社群 VSCode简称VSC,是Visual studio code的缩写,是由微软开发的跨平台的轻量级编辑器,支持几乎所有主流的开发语言的语法高亮、代码智能补全、插件扩展、代码对比等,…...
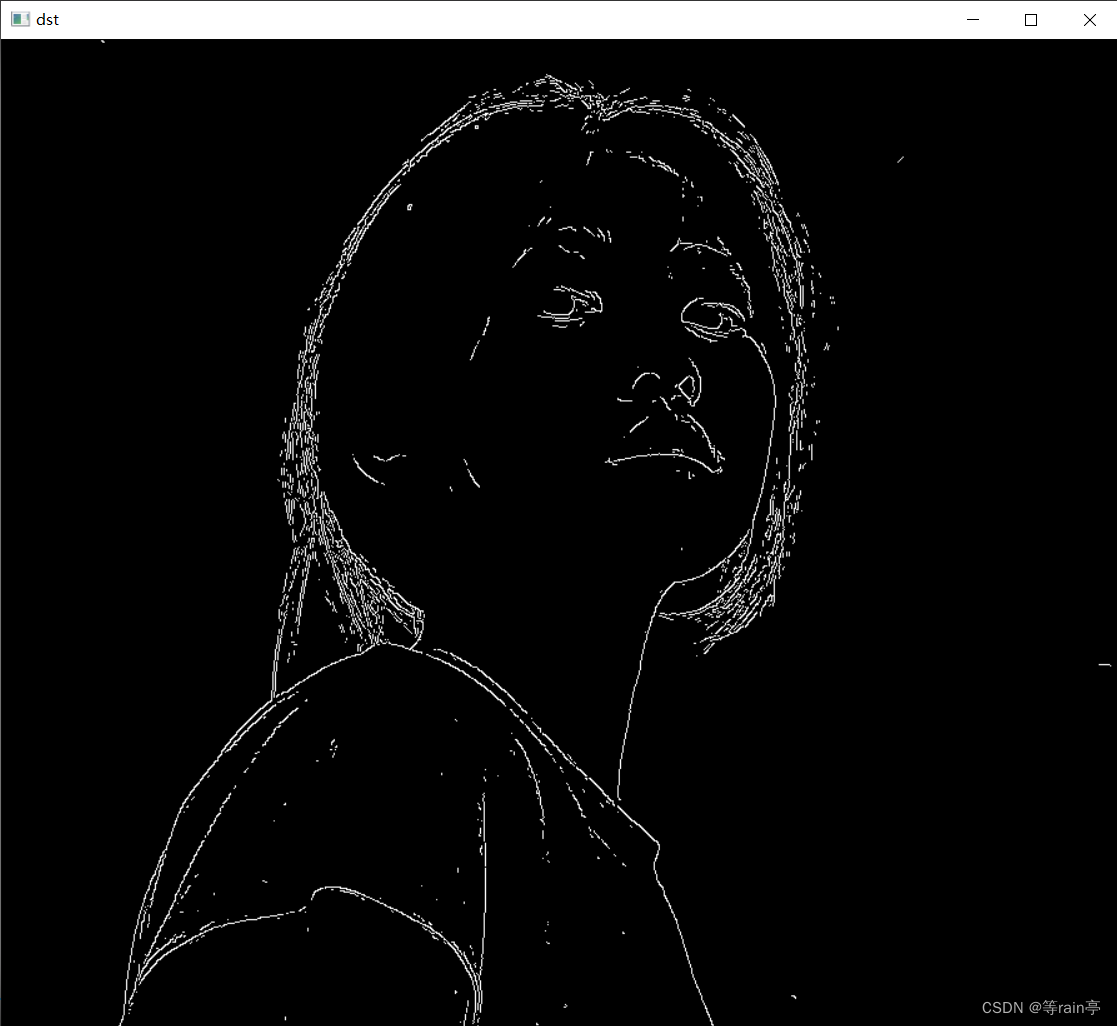
Opencv中的滤波器
一副图像通过滤波器得到另一张图像,其中滤波器又称为卷积核,滤波的过程称之为卷积。 这就是一个卷积的过程,通过一个卷积核得到另一张图片,明显发现新的到的图片边缘部分更加清晰了(锐化)。 上图就是一个卷…...

<JavaEE> 基于 TCP 的 Socket 通信模型
目录 一、认识相关API 1)ServerSocket 2)Socket 二、TCP字节流套接字通信模型概述 三、回显客户端-服务器 1)服务器代码 2)客户端代码 一、认识相关API 1)ServerSocket ServerSocket 常用构造方法ServerSocke…...
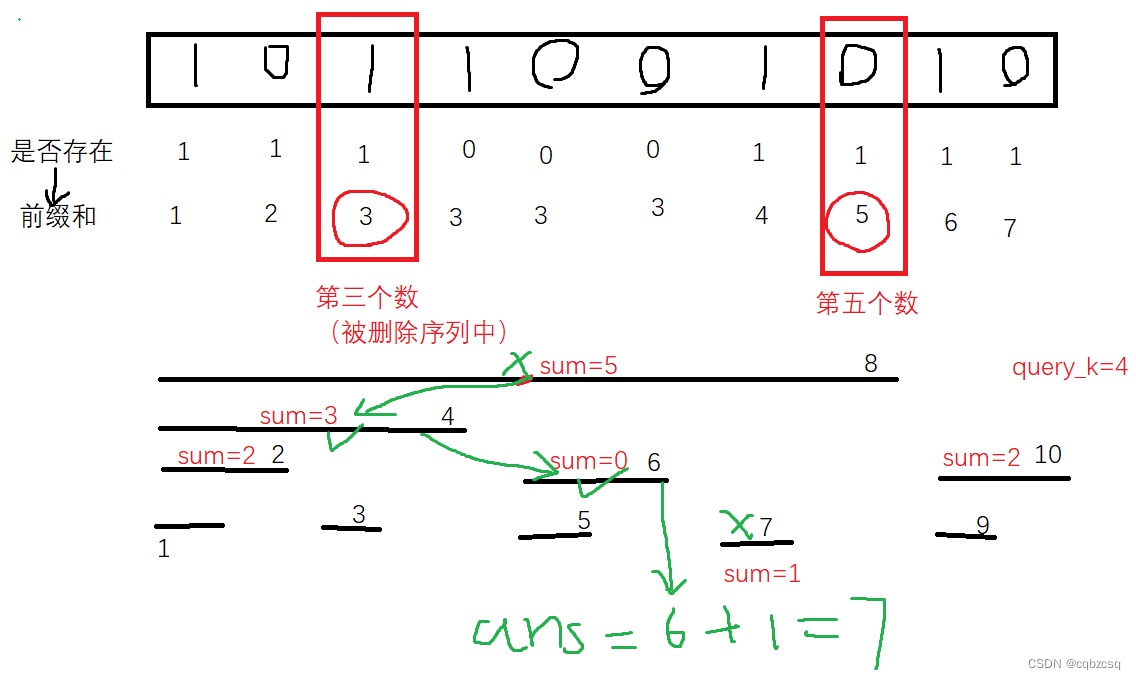
[THUPC 2024 初赛] 二进制 (树状数组单点删除+单点查询)(双堆模拟set)
题解 题目本身不难想 首先注意到所有查询的序列长度都是小于logn级别的 我们可以枚举序列长度len,然后用类似滑动窗口的方法,一次性预处理出每种字串的所有出现位置,也就是开N个set去维护所有的位置。预处理会进行O(logn)轮,每…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...
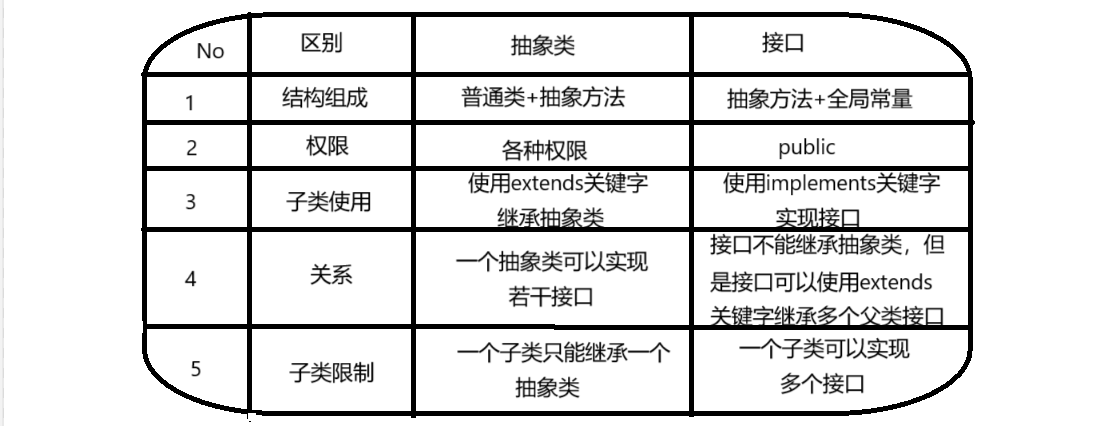
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...
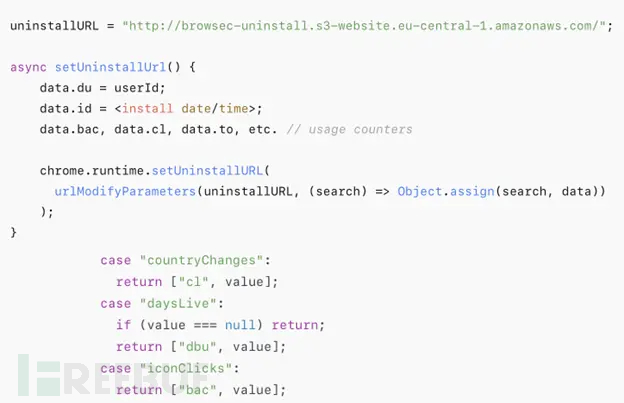
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...