探索迁移学习:通过实例深入理解机器学习的强大方法
探索迁移学习:通过实例深入理解机器学习的强大方法
- 🍁1. 迁移学习的概念
- 🍁2. 迁移学习的应用领域
- 🍁2.1 计算机视觉
- 🍁2.2 自然语言处理(NLP)
- 🍁2.3 医学图像分析
- 🍁2.4 语音识别
- 🍁3. 迁移学习的主要步骤
- 🍁4. 示例演示
- 🍁4.1 使用迁移学习进行图像分类
- 🍁4.2 使用GPT进行文本生成
- 🍁4.3 使用ResNet50进行图像分类
- 🍁5. 迁移学习的未来发展

🚀欢迎互三👉: 2的n次方_💎💎

迁移学习是一种利用在一个任务中学到的知识来帮助解决另一个任务的方法。在机器学习和深度学习中,迁移学习特别有用,因为它可以大幅减少训练模型所需的数据和时间。在这篇博客中,我们将探讨迁移学习的概念、应用领域,并通过一个代码示例展示如何在图像分类任务中应用迁移学习。
🍁1. 迁移学习的概念
迁移学习的基本思想是利用一个领域(源领域)中的知识来改进另一个领域(目标领域)中的学习效果。例如,在图像分类中,我们可以使用在大型数据集(如ImageNet)上预训练的神经网络,并将其应用于较小的、特定任务的数据集上。这种方法可以显著提高模型的性能,尤其是在目标数据集较小的情况下。
🍁2. 迁移学习的应用领域
🍁2.1 计算机视觉
计算机视觉是迁移学习应用最广泛的领域之一。预训练的深度卷积神经网络(如VGG、ResNet、Inception等)通常用于多种视觉任务。

图像分类:
图像分类是计算机视觉中的基本任务之一。迁移学习可以显著提高小数据集上的分类精度。通过使用在大型数据集(如ImageNet)上预训练的模型,可以将这些模型应用于特定的图像分类任务,如猫狗分类、花卉分类等。
目标检测:
目标检测是识别并定位图像中的多个对象。预训练模型如Faster R-CNN、YOLO和SSD,利用在大规模数据集上学到的特征,可以更快地适应新的目标检测任务,如交通标志检测、行人检测等。
图像分割:
图像分割将图像划分为多个有意义的部分。预训练的分割模型(如U-Net、DeepLab)可以用于医学图像分割(如器官分割、肿瘤分割)、场景理解等任务。
🍁2.2 自然语言处理(NLP)
NLP是迁移学习的另一个重要应用领域。预训练的语言模型(如BERT、GPT、RoBERTa等)已经彻底改变了NLP任务的性能。
文本分类:
文本分类包括新闻分类、垃圾邮件检测等。利用BERT等预训练模型,可以大幅提升文本分类的准确性和效率。
情感分析:
情感分析是识别文本中表达的情感。通过迁移学习,预训练的模型可以迅速适应不同领域的情感分析任务,如产品评论、社交媒体评论等。
机器翻译:
机器翻译是将一种语言翻译成另一种语言。迁移学习模型(如Transformer、mBERT)在翻译任务中表现出色,尤其是低资源语言对的翻译。
🍁2.3 医学图像分析
医学图像分析是一个对精度要求极高的领域,迁移学习在其中扮演了重要角色。

癌症检测:
癌症检测需要高精度的图像分类和分割模型。利用预训练的深度学习模型,可以提高癌症检测的准确性,如乳腺癌检测、皮肤癌检测等。
器官分割:
器官分割是将医学图像中的器官区域分割出来。预训练的模型(如U-Net、ResNet)在CT扫描和MRI图像的器官分割任务中表现出色,可以辅助医生进行诊断和治疗规划。
🍁2.4 语音识别
语音识别领域同样受益于迁移学习,预训练的模型显著提高了语音相关任务的性能。

语音到文本转换:
语音到文本转换(ASR)是将语音信号转换为文本。预训练的模型(如DeepSpeech、Wav2Vec)在多种语言的语音识别任务中表现出色,尤其是处理长尾音频数据和噪声音频。
情感识别:
情感识别是从语音信号中检测说话者的情感状态。迁移学习模型可以在不同情感数据集之间迁移,从而提高情感识别的准确性和鲁棒性。
🍁3. 迁移学习的主要步骤
迁移学习通过使用在大型数据集上预训练的模型,提高新任务的性能。以下是迁移学习的简要步骤:
1.选择在类似任务上表现优异的预训练模型(如VGG、ResNet、BERT等)。
2.使用深度学习框架(如TensorFlow、PyTorch)加载预训练模型。
3.冻结预训练模型的部分或全部层,以保留其学到的特征。
4.在预训练模型基础上添加新的层,以适应目标任务。
5.选择优化器、损失函数和评估指标,编译模型。
6.在目标数据集上训练模型,必要时解冻部分层进行微调。
7.使用验证集或测试集评估模型性能,并调整训练策略。
8.将经过微调和评估的模型部署到生产环境。
🍁4. 示例演示
🍁4.1 使用迁移学习进行图像分类
我们将使用Keras框架来展示迁移学习的一个简单应用。这里,我们将使用预训练的VGG16模型,并将其应用于一个小型的猫狗分类数据集。
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
from tensorflow.keras import layers, models, optimizers# 数据预处理
train_dir = 'path/to/train'
validation_dir = 'path/to/validation'train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(150, 150),batch_size=20,class_mode='binary'
)validation_generator = validation_datagen.flow_from_directory(validation_dir,target_size=(150, 150),batch_size=20,class_mode='binary'
)# 加载预训练的VGG16模型,不包括顶层的全连接层
conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))# 冻结VGG16的卷积基
conv_base.trainable = False# 构建新的模型
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))# 编译模型
model.compile(optimizer=optimizers.RMSprop(learning_rate=2e-5),loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
history = model.fit(train_generator,steps_per_epoch=100,epochs=30,validation_data=validation_generator,validation_steps=50
)# 可视化训练过程
import matplotlib.pyplot as pltacc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()plt.show()数据预处理:我们使用ImageDataGenerator来缩放图像并生成训练和验证数据。
加载预训练模型:我们加载预训练的VGG16模型,并冻结其卷积基,这样就不会在训练过程中更新这些层的权重。
构建新的模型:在卷积基之上添加新的全连接层。
编译模型:使用RMSprop优化器和二元交叉熵损失函数编译模型。
训练模型:在训练和验证数据上训练模型,并记录训练过程中的准确率和损失。
可视化训练过程:绘制训练和验证的准确率和损失曲线。
通过这种方式,我们利用VGG16在ImageNet上的预训练知识来改进猫狗分类任务的性能。
🍁4.2 使用GPT进行文本生成
GPT(Generative Pre-trained Transformer)是另一种强大的预训练模型,广泛应用于文本生成任务。我们将展示如何使用GPT进行文本生成。
from transformers import GPT2Tokenizer, TFGPT2LMHeadModel# 加载预训练的GPT2模型和分词器
model_name = "gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = TFGPT2LMHeadModel.from_pretrained(model_name)# 示例输入
input_text = "Once upon a time"
input_ids = tokenizer.encode(input_text, return_tensors='tf')# 生成文本
output = model.generate(input_ids, max_length=50, num_return_sequences=1)# 解码并打印生成的文本
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)🍁4.3 使用ResNet50进行图像分类
我们将展示如何使用ResNet50预训练模型进行图像分类任务。这里,我们将使用一个小型的花卉分类数据集。
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import ResNet50
from tensorflow.keras import layers, models, optimizers# 数据预处理
train_dir = 'path/to/train'
validation_dir = 'path/to/validation'train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(224, 224),batch_size=32,class_mode='categorical'
)validation_generator = validation_datagen.flow_from_directory(validation_dir,target_size=(224, 224),batch_size=32,class_mode='categorical'
)# 加载预训练的ResNet50模型,不包括顶层的全连接层
conv_base = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))# 冻结ResNet50的卷积基
conv_base.trainable = False# 构建新的模型
model = models.Sequential()
model.add(conv_base)
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(5, activation='softmax')) # 假设有5类花卉# 编译模型
model.compile(optimizer=optimizers.Adam(),loss='categorical_crossentropy',metrics=['accuracy'])# 训练模型
history = model.fit(train_generator,steps_per_epoch=100,epochs=30,validation_data=validation_generator,validation_steps=50
)# 可视化训练过程
import matplotlib.pyplot as pltacc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()plt.show()🍁5. 迁移学习的未来发展

1.更广泛的应用领域:随着技术的不断进步,迁移学习将在更多领域得到应用,如智能交通、智能制造、智能物流等,推动这些领域的发展和进步。
2.算法与技术的持续创新:为了解决现有挑战,迁移学习算法和技术将持续创新,涌现出更多高效、鲁棒的迁移学习模型和方法。
3.跨模态迁移学习:未来迁移学习可能会进一步扩展到跨模态领域,实现不同模态数据之间的知识和经验迁移,如文本到图像、语音到视频等。
4.结合其他机器学习技术:迁移学习可能会与深度学习、强化学习等其他机器学习技术更加紧密地结合,形成更强大的学习框架,提升学习性能和效果。
迁移学习的未来发展前景广阔,但也面临着诸多挑战。通过持续的技术创新和应用实践,相信迁移学习将在未来发挥更加重要的作用,为人工智能技术的发展和应用贡献力量。
相关文章:
探索迁移学习:通过实例深入理解机器学习的强大方法
探索迁移学习:通过实例深入理解机器学习的强大方法 🍁1. 迁移学习的概念🍁2. 迁移学习的应用领域🍁2.1 计算机视觉🍁2.2 自然语言处理(NLP)🍁2.3 医学图像分析🍁2.4 语音…...
:trace)
【Linux】性能分析器 perf 详解(四):trace
上一篇:【Linux】性能分析器 perf 详解(三) 1、trace 1.1 简介 perf trace 类似于 strace 工具:用于对Linux系统性能分析和调试的工具。 原理是:基于 Linux 性能计数器(Performance Counters for Linux, PCL),监控和记录系统调用和其他系统事件。 可以提供关于硬件…...

信息安全体系架构设计
对信息系统的安全需求是任何单一安全技术都无法解决的,要设计一个信息安全体系架构,应当选择合适的安全体系结构模型。信息系统安全设计重点考虑两个方面;其一是系统安全保障体系;其二是信息安全体系架构。 1.系统安全保障体系 安…...

GPT-5即将登场:AI赋能下的未来工作与日常生活新图景
随着OpenAI首席技术官米拉穆拉蒂在近期采访中的明确表态,GPT-5的发布已不再是遥不可及的梦想,而是即将在一年半后与我们见面的现实。这一消息无疑在科技界乃至全社会引发了广泛关注和热烈讨论。从GPT-4到GPT-5的飞跃,被形容为从高中生到博士生…...
RocketMQ实战:一键在docker中搭建rocketmq和doshboard环境
在本篇博客中,我们将详细介绍如何在 Docker 环境中一键部署 RocketMQ 和其 Dashboard。这个过程基于一个预配置的 Docker Compose 文件,使得部署变得简单高效。 项目介绍 该项目提供了一套 Docker Compose 配置,用于快速部署 RocketMQ 及其…...
前端项目vue3/React使用pako库解压缩后端返回gzip数据
pako仓库地址:https://github.com/nodeca/pako 文档地址:pako 2.1.0 API documentation 外部接口返回一个直播消息或者图片数据是经过zip压缩的,前端需要把这个数据解压缩之后才可以使用,这样可以大大降低网络数据传输的内容&…...

C++专业面试真题(1)学习
TCP和UDP区别 TCP 面向连接。在传输数据之前,通信双方需要先建立一个连接(三次握手)。可靠性。TCP提供可靠的数据传输,它通过序列号、确认应答、重传机制和校验和等技术确保数据的正确传输。数据顺序:TCP保证数据按发…...

2024 年人工智能和数据科学的五个主要趋势
引言 2023年,人工智能和数据科学登上了新闻头条。生成性人工智能的兴起无疑是这一显著提升曝光度的驱动力。那么,在2024年,该领域将如何继续占据头条,并且这些趋势又将如何影响企业的发展呢? 在过去几个月,…...

GPU云渲染平台到底怎么选?这六点要注意!
随着对高效计算和图像处理需求的增加,GPU云渲染平台成为许多行业的关键工具。尤其是对影视动画制作领域来说,选择一个合适的GPU云渲染平台可以大大提升工作效率。然而,面对市场上众多的选择,如何找到适合自己的GPU云渲染平台呢&am…...
【区块链+基础设施】国家健康医疗大数据科创平台 | FISCO BCOS应用案例
在医疗领域,疾病数据合法合规共享是亟待解决的难题。一方面,当一家医院对患者实施治疗后,若患者转到其 他医院就医,该医院就无法判断诊疗手段是否有效。另一方面,医疗数据属于个人敏感数据,一旦被泄露或被恶…...

redis压测和造数据方式
一、redis 压测工具 1、压测命令 1、对3000字节的数据进行get set的操作 redis-benchmark -h 10.166.15.36 -p 7001 -t set,get -n 100000 -q -d 3000 2、100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性能 redis-benchma…...

数据存储方案选择:ES、HBase、Redis、MySQL与MongoDB的应用场景分析
一、概述 1.1 背景 在当今数据驱动的时代,选择合适的数据存储技术对于构建高效、可靠的信息系统至关重要。随着数据量的爆炸式增长和处理需求的多样化,市场上涌现出了各种数据存储解决方案,每种技术都有其独特的优势和适用场景。Elasticsear…...

数组理论基础
1. **数组定义**: - 数组是存放在连续内存空间上的相同类型数据的集合。 2. **数组特性**: - 数组下标从0开始。 - 数组的内存空间地址是连续的。 3. **数组操作**: - 数组可以通过下标索引快速访问元素。 - 数组元素的删除…...

FlinkCDC 数据同步优化及常见问题排查
【面试系列】Swift 高频面试题及详细解答 欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: 欢迎关注微信公众号:野老杂谈 ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、…...

手把手edusrc漏洞挖掘和github信息收集
0x1 前言 这里主要还是介绍下新手入门edusrc漏洞挖掘以及在漏洞挖掘的过程中信息收集的部分哈!(主要给小白看的,大佬就当看个热闹了)下面的话我将以好几个不同的方式来给大家介绍下edusrc入门的漏洞挖掘手法以及利用github信息收…...
linux系统中的各种命令的解释和帮助(含内部命令、外部命令)
目录 一、说明 二、命令详解 1、帮助命令的种类 (1)help用法 (2)--help用法 2、如何区别linux内部命令和外部命令 三、help和—help 四、man 命令 1、概述 2、语法和命令格式 (1)man命令的格式&…...

Gemma轻量级开放模型在个人PC上释放强大性能,让每个桌面秒变AI工作站
Google DeepMind团队最近推出了Gemma,这是一个基于其先前Gemini模型研究和技术的开放模型家族。这些模型专为语言理解、推理和安全性而设计,具有轻量级和高性能的特点。 Gemma 7B模型在不同能力领域的语言理解和生成性能,与同样规模的开放模型…...
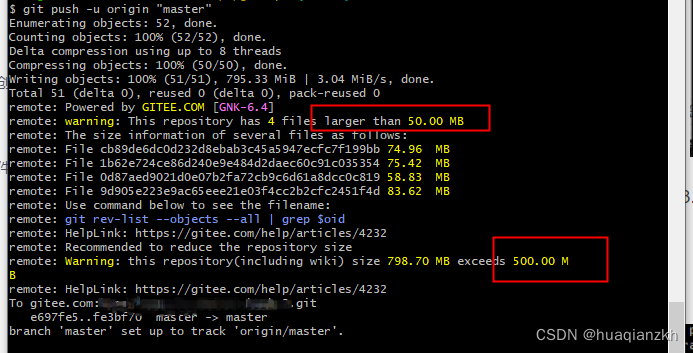
Git使用中遇到的问题(随时更新)
问题1.先创建本地库,后拉取远程仓库时上传失败的问题怎么解决? 操作主要步骤: step1 设置远程仓库地址: $ git remote add origin gitgitee.com:yourAccount/reponamexxx.git step2 推送到远程仓库: $ git push -u origin "master&qu…...

php 跨域问题
设置header <?php $origin isset($_SERVER[HTTP_ORIGIN])? $_SERVER[HTTP_ORIGIN]:;$allow_originarray(http://www.aaa.com,http://www.bbb.com, ); if( $origin in $allow_origin ){header("Access-Control-Allow-Origin:".$origin);header("Access-Co…...

【leetcode52-55图论、56-63回溯】
图论 回溯...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...