基于深度学习的车牌检测系统的设计与实现(安卓、YOLOV、CRNNLPRNet)+文档
💗博主介绍💗:✌在职Java研发工程师、专注于程序设计、源码分享、技术交流、专注于Java技术领域和毕业设计✌
温馨提示:文末有 CSDN 平台官方提供的老师 Wechat / QQ 名片 :)Java精品实战案例《700套》
2025最新毕业设计选题推荐:最热的500个选题o( ̄▽ ̄)d
介绍
[摘 要] 随着交通管理的智能化发展,我们知道基于深度学习的车牌检测系统在安全监控和交通管理等领域发挥着关键作用,然而传统车牌识别方法受复杂场景和光照条件影响,性能还不够高,所以本文设计了一种采用YOLOv5模型进行车牌检测,并结合PlateNet模型进行车牌识别的系统,目的在于在提高车牌识别的准确性和效率。我们通过深度学习技术,使该系统实现了对车牌的快捷且精准的检测与识别,并且还提出一些优化方案,包括数据预处理与模型设计以及参数调优,从而提升系统在复杂环境下的鲁棒性。本次实验通过大量实验验证,证明该系统在不同场景和光照条件下可以取得较好的效果,实现了对车辆行驶状态的实时监测和识别。所以该系统在提高交通安全、优化交通管理和提升道路通行效率方面具有广泛应用前景,本研究对深度学习在车牌检测技术领域的探索,以及智能交通系统的进一步发展具有重要意义。
[关键词] 深度学习;车牌检测;YOLOv5;PlateNet
演示视频
基于深度学习的车牌检测系统的设计与实现(安卓、YOLOV、CRNNLPRNet)+文档_哔哩哔哩_bilibili
系统功能
- 模型选择及搭建
我们为了解决传统车牌识别方法效率与准确率不高的问题,采用基于深度学习的无分割车牌识别方法。通过构建车牌检测和识别系统,利用YOLOv5进行车牌检测,结合PlateNet模型进行车牌识别。同时,针对端上部署需求,提出了 PlateNet模型,支持部署到Android SDK或开发板。
车牌号码是车辆身份的重要标识,其编制规则反映了一定的地理和行政管理信息。根据中国的车牌编制规则,车牌号码的第一位是汉字,代表车辆所在省级行政区的 简称,比如“京”代表北京,“沪”代表上海,“粤”代表广东。第二位是英文字 母,表示车辆所在地级行政区的代码,例如“A”代表省会或直辖市中心区域, “B”、“C”、“D”等依次代表其他地级市。在字母编制过程中,通常跳过了"I" 和"O",因为它们容易与数字“1”和“0”混淆。车牌号码后续的字符则代表车辆的 具体编号。
车牌还分为蓝牌和绿牌两种类型。蓝牌车辆是传统燃油车辆的标识,采用纯蓝色设计,字体为白色,号码共有7位字符。绿牌车辆是新能源汽车的标识,采用渐变绿或黄绿双拼色设计,字体为黑色,号码长度为8位字符,其中包括省份简称、地市代码和车辆序号等信息。
CCPD(Chinese City Parking Dataset)是中国城市车牌数据集的缩写,分为 CCPD2019(图3-1)和CCPD2020(图3-2)两个版本。CCPD2019主要包含蓝牌数据,约有30万张图片,而CCPD2020则主要收集了新能源绿牌数据,约有1万张图片。这些数据集是由中国各地城市停车场拍摄获得的,涵盖了多种场景下的车牌图像,包括倾斜、模糊、雨雪天气等。我们同时使用了这两个数据集进行训练,使系统可以在更多环境下进行较为良好的识别检测且可以检测蓝绿两种车牌。
图 3‑1 CCPD2019数据集
表 3‑1 CCPD2019数据集类型说明
| 类型 | 图片数 | 说明 |
| ccpd_base | 199998 | 正常车牌 |
| ccpd_challenge | 10006 | 比较有挑战的车牌 |
| ccpd_db | 20001 | 光线较暗或较亮车牌 |
| ccpd_fn | 19999 | 距离摄像头较远或较近 |
| ccpd_np | 3036 | 没上牌的新车 |
| ccpd_rotate | 9998 | 水平倾斜20-50度,垂直倾斜-10-10度 |
| ccpd_tilt | 10000 | 水平倾斜15-45度,垂直倾斜-15-45度 |
| ccpd_weather | 9999 | 雨天、雪天或大雾的车牌 |
图 3‑2 CCPD2020数据集
我们使用了一种直观清晰的命名规则对CCPD数据集的格式进行标注,以方便数据的管理和处理。CCPD车牌数据集标注了车牌四个角点,车牌水平和垂直角度以及车牌号码等信息,并以图片文件名的方式进行命名(图3-3),如【025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg】,其文件名的含义如下表3-2:
表 3‑2文件名含义对照表
| 命名 | 具体含义 |
| 025 | 车牌区域占整个画面的比例 |
| 95_113 | 车牌水平和垂直角度, 水平95°, 竖直113° |
| 154&383_386&473 | 标注框左上、右下坐标,左上(154, 383), 右下(386, 473) |
| 86&473_177&454_154&383_363&402 | 标注框四个角点坐标,顺序为右下、左下、左上、右上 |
| 025 | 车牌区域占整个画面的比例; |
| 0_0_22_27_27_33_16 | 第一个0为省份 对应省份字典provinces中的’皖’,;第二个0是该车所在地的地市一级代码,对应地市一级代码字典alphabets的’A’;后5位为字母和文字, 查看车牌号ads字典,如22为Y,27为3,33为9,16为S,最终车牌号码为皖AY339S。 |
车牌号码映射关系如下:
| def get_plate_licenses(plate): provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"] alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'O'] ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O'] result = [provinces[int(plate[0])], alphabets[int(plate[1])]] result += [ads[int(p)] for p in plate[2:]] result = "".join(result) # 新能源车牌的要求,如果不是新能源车牌可以删掉这个if # if result[2] != 'D' and result[2] != 'F' \ # and result[-1] != 'D' and result[-1] != 'F': # print(plate) # print("Error label, Please check!") print(plate, result) return result |
这种标注格式使我们在研究中可以迅速理解和利用数据集中的信息,为车牌检测算法的开发和评估提供了便利。
数据预处理是机器学习和深度学习应用中的关键步骤,它对模型的性能和训练效果有重要影响。在车牌检测和识别任务中,数据预处理主要包括以下几个方面:
1. 数据清洗:我们知道在数据集中可能存在一些质量不佳的图像,所以我们在数据预处理阶段,需要去除这些质量较差或重复的图像,以确保数据集的质量和模型训练的稳定性。我们先用代码去掉完全相同的图片,我们通过分别比较图片的大小与尺寸以及内容像素是否相同,从而判断图片是否相同。
| def 比较图片大小(dir_image1, dir_image2): with open(dir_image1, "rb") as f1: size1 = len(f1.read()) with open(dir_image2, "rb") as f2: size2 = len(f2.read()) if (size1 == size2): result = "大小相同" else: result = "大小不同" return result def 比较图片尺寸(dir_image1, dir_image2): image1 = Image.open(dir_image1) image2 = Image.open(dir_image2) if (image1.size == image2.size): result = "尺寸相同" else: result = "尺寸不同" return result def 比较图片内容(dir_image1, dir_image2): image1 = np.array(Image.open(dir_image1)) image2 = np.array(Image.open(dir_image2)) if (np.array_equal(image1, image2)): result = "内容相同" else: result = "内容不同" return result def 比较两张图片是否相同(dir_image1, dir_image2): result = "两张图不同" 大小 = 比较图片大小(dir_image1, dir_image2) if (大小 == "大小相同"): 尺寸 = 比较图片尺寸(dir_image1, dir_image2) if (尺寸 == "尺寸相同"): 内容 = 比较图片内容(dir_image1, dir_image2) if (内容 == "内容相同"): result = "两张图相同" return result |
我们还使用opencv提供的拉普拉斯算子接口求得图片清晰度数值,通过拉普拉斯算子计算图片的二阶导数,反映图片的边缘信息,同样事物的图片,清晰度高的,相对应的经过拉普拉斯算子滤波后的图片的方差也就越大,数值越小的,清晰度越低,也就越模糊,同时对图片进行排序,最后移除最模糊的%10的图片。
| def getImageVar(imgPath): image = cv2.imread(imgPath) img2gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) imageVar = cv2.Laplacian(img2gray, cv2.CV_64F).var() return imageVar if __name__ == "__main__": src_img_dir = r"D:\data\img_dir" move_img_dir = r"D:\data\img_dir_blur" os.makedirs(move_img_dir, exist_ok=True) img_files = os.listdir(src_img_dir) print("len(img_files): ", len(img_files)) a_list = [] for i in range(len(img_files)): img_file_path = os.path.join(src_img_dir, img_files[i]) imageVar = getImageVar(img_file_path) # print(imageVar) a = item() a.val = imageVar a.name = img_files[i] a_list.append(a) print("len(a_list): ", len(a_list)) a_list.sort(key=lambda ita: ita.val, reverse=False) # 按照 图片清晰度排序,模糊的放在列表头部,清晰的放在列表尾部 count = 0 for i in range(int(len(a_list)*0.1)): # 移除最模糊的 %10 的图片 print(a_list[i].name, a_list[i].val) src_path = os.path.join(src_img_dir, a_list[i].name) dest_path = os.path.join(move_img_dir, a_list[i].name) shutil.move(src_path, dest_path) count += 1 # break print("count: ", count) |
- 数据增强:在训练中,要求样本数量充足,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强,所以为了提高模型的鲁棒性和泛化能力,我们通过数据增强技术对这些数据进行处理(图3-4),从而增加样本数量以增加数据集的多样性。
图 3‑4 样本处理对比
图像的翻转是以图像的中心为中轴线进行翻转的。我们将图像的坐标系原点设置在图像的中心,x轴向右延伸,y轴向下延伸。我们设x 和 y 是原始图像中的坐标,x’ 和 y’ 是翻转后图像中的坐标,w和h分别表示图像的宽度和高度,在这个坐标系下,进行图像翻转的原理如下:
垂直翻转:以图像中心为中轴线,对图像进行上下翻转, 翻转后,图像中每个像素点的新坐标为 (x’, y’),其中 x’ 的计算公式为 x’ = x,而 y’ 的计算公式为 y’ = h - 1 - y。这里的 h 是图像的高度,即图像的行数。
x'y'1=1000-1h-1001xy1#3-1
| def flip(root_path,img_name): #翻转图像 img = Image.open(os.path.join(root_path, img_name)) filp_img = img.transpose(Image.FLIP_LEFT_RIGHT) # filp_img.save(os.path.join(root_path,img_name.split('.')[0] + '_flip.jpg')) return filp_img |
水平翻转:以图像中心为中轴线,对图像进行左右翻转, 翻转后,图像中每个像素点的新坐标为 (x’, y’),其中 x’ 的计算公式为 x’ = w - 1 - x,而 y’ 的计算公式为 y’ = y。这里的 w是图像的宽度,即图像的列数。
x'y'1=-10w-10-1w-1001xy1#3-2
| def rotation(root_path, img_name): img = Image.open(os.path.join(root_path, img_name)) random_angle = np.random.randint(-2, 2)*90 if random_angle==0: rotation_img = img.rotate(-180) #旋转角度 else: rotation_img = img.rotate( random_angle,expand=True) # 旋转角度 # rotation_img.save(os.path.join(root_path,img_name.split('.')[0] + '_rotation.jpg')) return rotation_img |
亮度增强是对图片的每个像素点的三通道值进行同步放大,同时保持通道值在0-255之间。
| def enhance_mycode(img): imgHeight,imgWidth,imgDeep = img.shape dst1 = np.zeros((imgHeight, imgWidth, 3), np.uint8) for i in range(0, imgHeight): for j in range(0, imgWidth): (b, g, r) = map(int,img[i,j]) b += 40 g += 40 r += 40 if b > 255: b = 255 if g > 255: g = 255 if r > 255: r = 255 dst1[i, j] = (b, g, r) return dst1 def enhance_api(img): dst2 = np.uint8(np.clip((1.5 * img ), 0, 255)) return dst2 |
3. 标注数据:我们使用Labelimg工具(图3-5)对数据集中的图像进行标注,新建一个文件夹,里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片,再创建一个名为Annotations存放标注的标签文件,最后创建一个名为 test.txt 的txt文件来存放所要标注的类别名称。
图 3‑5 labelimg工具
4. 数据分割:将数据集划分为训练集和测试集,训练集与测试集互斥,且我们需要保持训练集与测试集的数据划分一致性避免因数据划分过程引入额外的偏差而对最终结果产生影响,确保模型在不同阶段的性能评估和泛化能力。我们使用留出法对数据进行分割,将大约2/3~4/5的样本用于训练,剩余样本用于测试,代码如下:
| from sklearn.model_selection import train_test_split #使⽤train_test_split划分训练集和测试集 train_X , test_X, train_Y ,test_Y = train_test_split( X, Y, test_size=0.2,random_state=0) |
5. 格式转换:我们根据模型训练的需求,如果通过labelimg直接得到txt标签文本是不用进行转换就可以提供给YOLO进行训练的;如果是保存的XML文本,则需要通过下面代码进行转换。
| def ConverCoordinate(imgshape, bbox): # 将xml像素坐标转换为txt归一化后的坐标 xmin, xmax, ymin, ymax = bbox width = imgshape[0] height = imgshape[1] dw = 1. / width dh = 1. / height x = (xmin + xmax) / 2.0 y = (ymin + ymax) / 2.0 w = xmax - xmin h = ymax - ymin # 归一化 x = x * dw y = y * dh w = w * dw h = h * dh return x, y, w, h |
这些格式通常包含图像文件和对应的标注文件,方便模型在训练和评估阶段进行处理。
6. 数据归一化:我们在训练模型之前,需要对图像数据进行归一化处理;
归一化有三种类型: Min-max normalization (Rescaling)(3-3):归一化后的数据范围为 [0, 1],其中 min(x)和max(x) 分别求样本数据的最小值和最大值 。
x'=x-minxmaxx-minx#3-3
Mean normalization(3-4):归一化后的数据范围为 [-1, 1],其中 mean(x) 为样本数据的平均值。
x'=x-meanxmaxx-minx#3-4
但Min-max归一化和mean归一化适合在最大最小值明确不变的情况下使用,一是如果 max和min不稳定,很容易使得归一化的结果不稳定,使得后续使用效果也不稳定。如果遇到超过目前属性[min,max]取值范围的时候,会引起系统报错,需要重新确定min和max;二是如果数值集中的某个数值很大,则规范化后各值接近于0,并且将会相差不大。
Z-score归一化也可称为标准化,经过处理的数据呈均值为0,标准差为1的分布。在数据存在异常值、最大最小值不固定的情况下,可以使用标准化。标准化会改变数据的状态分布,但不会改变分布的种类。
但是我们通过归一化可以将数据映射到指定的范围内进行处理,更加便捷快速;还能把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。经过归一化后,将有量纲的数据集变成纯量,还可以达到简化计算的作用。
通过对数据集进行这些预处理步骤(图3-6),可以提高模型训练的效果和性能,进而提高车牌检测和识别任务的准确性和鲁棒性。



系统截图




















相关技术介绍
随着交通管理和安全监控需求的增加,基于深度学习的车牌检测系统变得日益重要。本章将介绍与本课题相关的关键技术,包括Python语言、Android SDK、YOLOv5模型和 PlateNet模型。Python作为一种高级编程语言,在数据处理、模型训练和系统开发等方面 发挥着重要作用。Android SDK为基于深度学习的车牌检测系统提供了强大的运行环境和 丰富的应用支持。YOLOv5模型作为一种高效的目标检测模型,在车牌检测中具有重要地 位,能够快速准确地定位和识别车牌。 PlateNet模型则专注于车牌识别,与YOLOv5模型 配合使用,实现了对车牌的快速定位和准确识别。
-
- 车牌检测技术概述
车牌检测技术是指利用计算机视觉和深度学习技术,对图像或视频中的车辆车牌进行准确地定位和识别的方法。该技术通常涉及到目标检测、图像处理和模式识别等领域的知识。基于深度学习的车牌检测技术,如YOLOv5等模型,能够快速而准确地识别图像中的车牌区域,实现对车牌的有效定位。随着技术的不断发展,车牌检测技术在智能交通、安防监控等领域得到了广泛应用,为提高交通管理效率和城市安全水平提供了重要支持。其关键挑战包括光照条件、遮挡情况、车牌样式和角度的多样性等。因此,车牌检测技术的发展需要不断优化算法和模型,以应对复杂场景下的各种挑战,提高检测的准确性和鲁棒性。
Python是一种高级编程语言,以其简洁易读的语法和丰富的库而闻名。在基于深度学习的车牌检测系统中,Python被广泛应用于数据处理、模型训练和系统开发等方面。通过 Python的强大库如NumPy、Pandas和OpenCV,可以高效地进行图像处理和数据操作,为车牌检测系统提供可靠的基础支持[10]。同时,深度学习框架使得模型训练和优化更加便捷。此外,Python的跨平台特性也使得系统可以轻松在不同操作系统上部署和运行,为系统的可移植性提供了便利。Python语言的灵活性和强大的生态系统为基于深度学习的车牌检测系统的开发和应用提供了可靠的技术支持[11]。
Android SDK是全球领先的移动操作系统之一,基于Linux内核开发,广泛应用于智能手机、平板电脑和其他移动设备[17]。在基于深度学习的车牌检测系统中, Android SDK提供了强大的运 行环境和丰富的应用支持。通过Android开发工具包[12]。
(Android SDK),开发人员可以轻松构建用户友好的应用界面,并利用Android Studio等开发工具进行应用程序的开发和调试。Android SDK的开放性和灵活性使得系统可以充分利用移动设备的计算能力和传感器资源,实现实时的车牌检测和识别功能。同时,Android SDK的广泛普及也为基于深度学习的车牌检测系统的推广和应用提供了良好的市场基础[13]。因此,Android SDK在基于深度学习的车牌检测系统的开发和部署中具有重要的意义和价值。
YOLOv5是一种高效的目标检测模型,采用了轻量化的设计和先进的深度学习技术,在车牌检测系统中发挥着重要作用。相比于之前的版本,YOLOv5模型[11]具有更高的检测精度和更快的推理速度,适用于移动设备和嵌入式系统。在基于深度学习的车牌检测系统中,YOLOv5模型能够快速准确地定位和识别车牌,即使在复杂的环境条件下也能表现出 色。其轻量化的特性使得在Android SDK上能够实现实时的车牌检测功能,满足实际应用的需求。同时,YOLOv5模型的开源性和灵活性也为系统的定制和优化提供了便利[14]。因此, YOLOv5作为车牌检测系统的核心组件,为系统的高效运行和准确识别提供了可靠的支持。
PlateNet是一种专门用于车牌识别的深度学习模型,在基于深度学习的车牌检测系统中扮演着关键角色。PlateNet模型结合了先进的字符识别技术和深度学习算法,能够准确地识别车牌上的字符信息,并支持绿牌和蓝牌的识别。在系统中,PlateNet模型与YOLOv5等车牌检测模型配合使用,实现了对车牌的快速定位和准确识别。PlateNet模型的高准确性和鲁棒性使得系统能够在各种复杂场景下有效运行,包括光照变化、遮挡等情况。其设计的轻量化特性也确保了在Android SDK上的高效运行和实时识别能力[15]。因此, PlateNet作为系统的重要组成部分,为车牌识别提供了可靠的技术支持,使得整个系统能够实现高效、准确的车牌检测与识别功能。
-
- 深度学习介绍
深度学习[9]是一种基于神经网络的机器学习方法,它模仿人脑神经元的工作方式,通过建立多层神经网络来学习和表示数据中的复杂特征。深度学习方法通过训练大型神经网络,从大量数据中提取有用的信息,实现对数据的分类、识别和预测等任务。其独特之处在于能够自动学习和抽象出数据中的多层次特征,而不需要人工设计特征[16]。
深度学习技术在各个领域中得到了广泛的应用,包括图像识别、自然语言处理、语音识别和自动驾驶等。在图像识别中,深度学习技术可以处理复杂的视觉问题,包括目标检测和图像分类。通过使用卷积神经网络(CNN)等模型[3],深度学习技术能够有效地捕捉图像中的空间特征,提高识别的准确性和鲁棒性。深度学习技术为解决复杂数据问题提供了强大的工具和方法。越来越多的人在车牌检测中开始应用深度学习技术,这项技术的发展为实现高效、准确的车牌识别提供了新的可能性。我们通过深度学习技术,特别是基于卷积神经网络(CNN)的模型,使这项系统能够自动学习图像中的特征,并准确地定位车牌区域。
深度学习模型如YOLO(You Only Look Once)和Faster R-CNN等已成为车牌检测领域的主流方法。这些模型具有强大的特征学习能力和目标检测能力,能够在复杂背景和各种场景中高效地检测车牌。特别是YOLO系列模型,其快速的检测速度和良好的准确性使其成为车牌检测领域的热门选择。
深度学习技术在车牌检测中的应用还使得系统能够适应不同的光照条件、角度变化 和遮挡情况。这些模型通过大规模数据集的训练,能够学习到车牌的多样性和变化规律,从而使系统的鲁棒性和泛化能力大大提高。
另外,深度学习技术还促进了车牌检测系统的实时性能。通过优化算法和模型结构,以及硬件加速技术的应用,使得车牌检测系统能够在实时视频流中快速而准确地检测车 牌,满足了交通管理和安全监控等领域对实时性的需求。
总体而言,深度学习在车牌检测中的应用极大地推动了该领域的发展,为提高交通管理效率和城市安全水平提供了有效的技术支持。
国内外研究现状
-
-
- 国内研究现状
-
国内车牌检测的研究一直是人工智能领域的一个重要方向,许多研究者和机构在这个领域取得了突出的成果。在国内研究现状中,存在着修订对不同算法和技术的深入探索。
传统的车牌检测方法[3]主要基于图像处理和机器学习算法。这些方法通过边缘检测、颜色过滤、形状匹配等技术对车牌区域进行提取和识别。然而,这些方法在复杂场景下,如光照条件变化、车牌遮挡和多样化车牌样式等情况下表现不佳。为了提高车牌检测的准确性和效率,研究者们开始引入深度学习算法。
在基于深度学习的车牌检测领域,国内研究者开发了多种模型。部分研究者采用卷积神经网络(CNN)进行车牌检测[3],这种方法通过对大量车牌数据集进行训练,实现对车牌的高效检测和识别。然而,传统的CNN模型在复杂场景下的性能表现仍然存在不足,如处理速度和鲁棒性等方面[4]。
为了进一步提高车牌检测的可靠性,人们尝试了基于区域的卷积神经网络(R-CNN)、单阶段目标检测模型(如SSD)等许多新型网络结构。这些模型在车牌检测中表现出了较以往相比更优秀的实时性和准确性。但是,这些方法在模型复杂度和计算资源方面也提出了更高的要求。
近些年来,国内研究者开始关注基于YOLO系列(包括YOLOv3、YOLOv4)的模型。这些模型在车牌检测领域展现出了较高的准确性和实时性,得到了广泛的关注和应用。同时,基于YOLO的模型在多样化场景下的鲁棒性得到了验证[4]。
经过深入分析和对比国内外研究成果,本研究采用了基于YOLOv5模型的车牌检测技术。YOLOv5模型在确保高精确度的前提下,展现出卓越的快速检测能力和较低的计算资源消耗。为了进一步增强车牌识别的准确度,本还研究融合了PlateNet模型,该模型在国内研究中表现出色。在本研究中,我们巧妙地结合了这些深度学习模型,期望构建一个更高效且精确以及具有较强鲁棒性的车牌检测与识别系统。
-
-
- 国外研究现状
-
国外在车牌检测领域的研究相较于国内更加先进,许多研究机构在这项领域的技术开发中取得了先进的成果。
国外研究者通常采用先进的卷积神经网络(CNN)模型进行车牌检测,这种方法通过在大量车牌数据集上进行训练,能够实现对车牌的高精度识别。早期的研究主要采用简单的CNN结构,这些模型在处理简单场景下表现良好,但在复杂环境和多样化的车牌样式下,其性能往往有所下降[5]。
随着深度学习技术的不断进步,国外研究者逐渐采用更加复杂的网络结构,如R-CNN、Faster R-CNN等。R-CNN通过区域选择和分类的结合,提高了车牌检测的准确性,而Faster R-CNN则进一步提高了模型的实时性。这些改进模型在复杂场景下展现了较高的鲁棒性和可靠性,但其模型复杂度和计算资源消耗较大[6]。
近年来,国外研究者开始关注单阶段目标检测模型,包括SSD和YOLO。这些模型在保持较高检测速度的同时,仍能实现较高的准确性。尤其是YOLO系列模型因其快速、高效的特点在车牌检测领域得到了广泛的应用和认可。YOLO模型在处理多样化场景和快速移动目标方面表现出色,成为许多研究者和公司的首选[7]。
此外,国外研究者也在探索其他新兴技术,如GAN(生成对抗网络)和强化学习,以进一步改进车牌检测的准确性和鲁棒性。这些技术在处理模糊、低光照和遮挡等复杂场景时表现出了一定的优势[8]。
通过对海外研究现状的深入探究和对比分析各类先进模型,我们精心挑选了YOLOv5模型作为车牌识别的技术核心。相对于其他模型,这个模型不仅精准度高,更具备卓越的效率和极低的资源耗费,这一特性对于车牌检测的实际应用场景显得至关重要。我们还融合了PlateNet模型,显著提升了车牌辨识的准确度,致力于打造一个全面而可靠的车牌检测系统。
功能代码
# Project-wide Gradle settings.
# IDE (e.g. Android Studio) users:
# Gradle settings configured through the IDE *will override*
# any settings specified in this file.
# For more details on how to configure your build environment visit
# http://www.gradle.org/docs/current/userguide/build_environment.html
# Specifies the JVM arguments used for the daemon process.
# The setting is particularly useful for tweaking memory settings.
org.gradle.jvmargs=-Xmx2048m -Dfile.encoding=UTF-8
# When configured, Gradle will run in incubating parallel mode.
# This option should only be used with decoupled projects. More details, visit
# http://www.gradle.org/docs/current/userguide/multi_project_builds.html#sec:decoupled_projects
# org.gradle.parallel=true
# AndroidX package structure to make it clearer which packages are bundled with the
# Android operating system, and which are packaged with your app"s APK
# https://developer.android.com/topic/libraries/support-library/androidx-rn
android.useAndroidX=true
# Automatically convert third-party libraries to use AndroidX
android.enableJetifier=true
android.injected.testOnly=false
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
相关文章:
基于深度学习的车牌检测系统的设计与实现(安卓、YOLOV、CRNNLPRNet)+文档
💗博主介绍💗:✌在职Java研发工程师、专注于程序设计、源码分享、技术交流、专注于Java技术领域和毕业设计✌ 温馨提示:文末有 CSDN 平台官方提供的老师 Wechat / QQ 名片 :) Java精品实战案例《700套》 2025最新毕业设计选题推荐…...
JavaWeb——JS、Vue
目录 1.JavaScript a.概述 b.引入方式 c.JS的基础语法 d.JS函数 e.JS对象 f.JS事件监听 2.Vue a.概述 b.Vue常用指令 d.生命周期 1.JavaScript a.概述 JavaScript是一门跨平台、面向对象的脚本语言。是用来控制网页行为的,它能使网页可交互。JavaScript和…...

Springboot 整合 Java DL4J 构建股票预测系统
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...
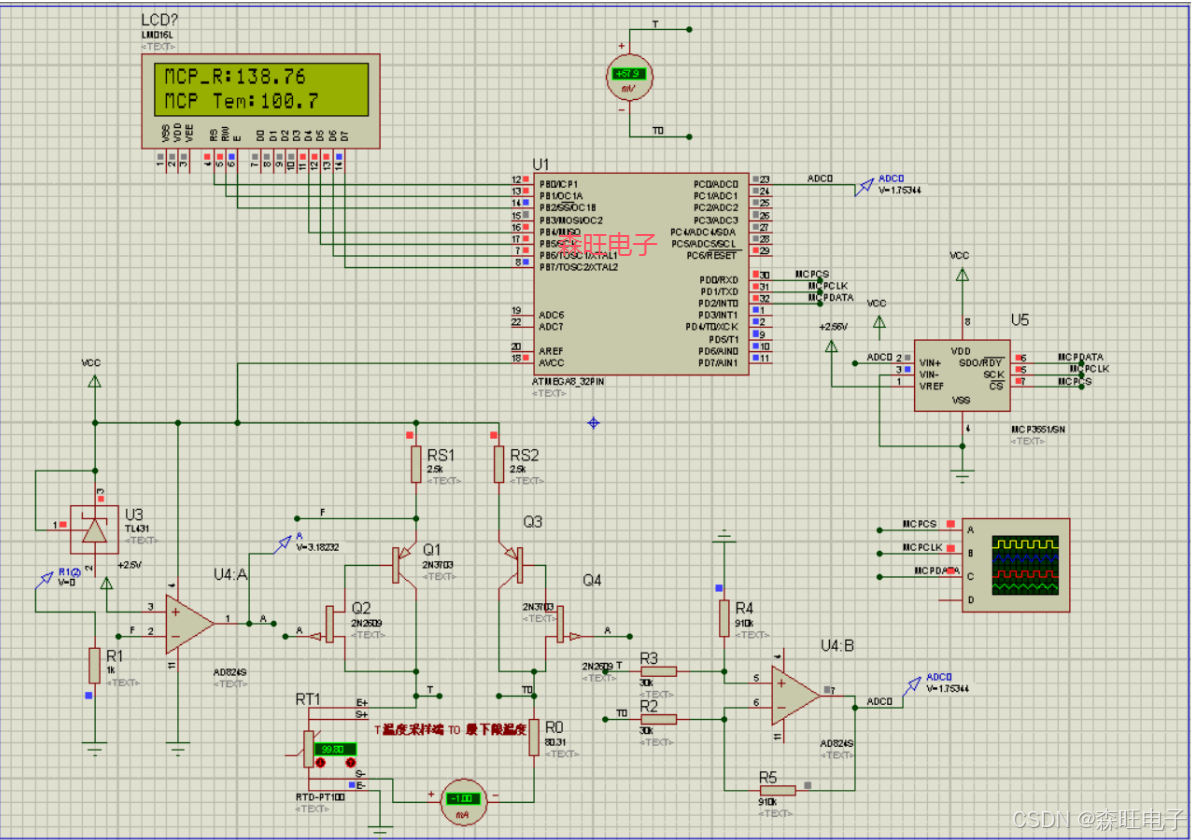
ATmaga8单片机Pt100温度计源程序+Proteus仿真设计
目录 1、项目功能 2、仿真图 3、程序 资料下载地址:ATmaga8单片机Pt100温度计源程序Proteus仿真设计 1、项目功能 设计Pt100铂电阻测量温度的电路,温度测量范围是0-100摄氏度,要求LCD显示。画出电路图,标注元器件参数&am…...
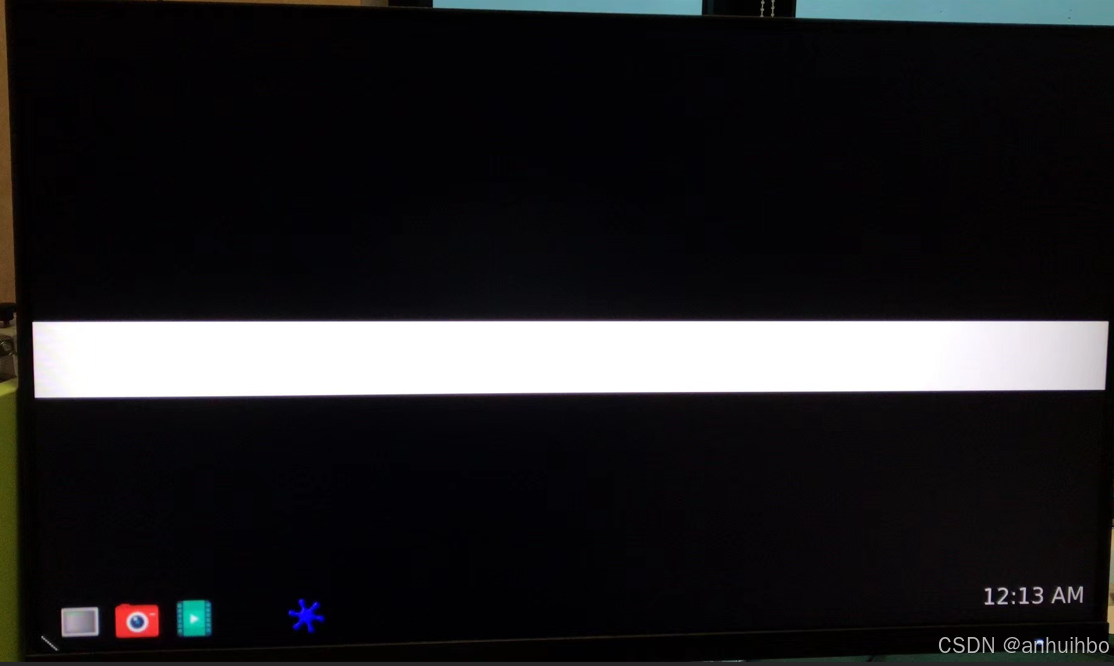
FPGA通过MIPI CSI-2发送实时图像到RK3588,并HDMI显示
介绍FPGA通过MIPI CSI-2发送实时图像到RK3588,并HDMI显示。 FPGA本地产生动态图像模板,通过MIPI CSI-2接口发送到RK3588 MIPI CSI接口。RK3588注册成相机后,调用接口并在HDMI显示器上显示。 1、RK3588驱动调试 查看Media controller信息 Med…...
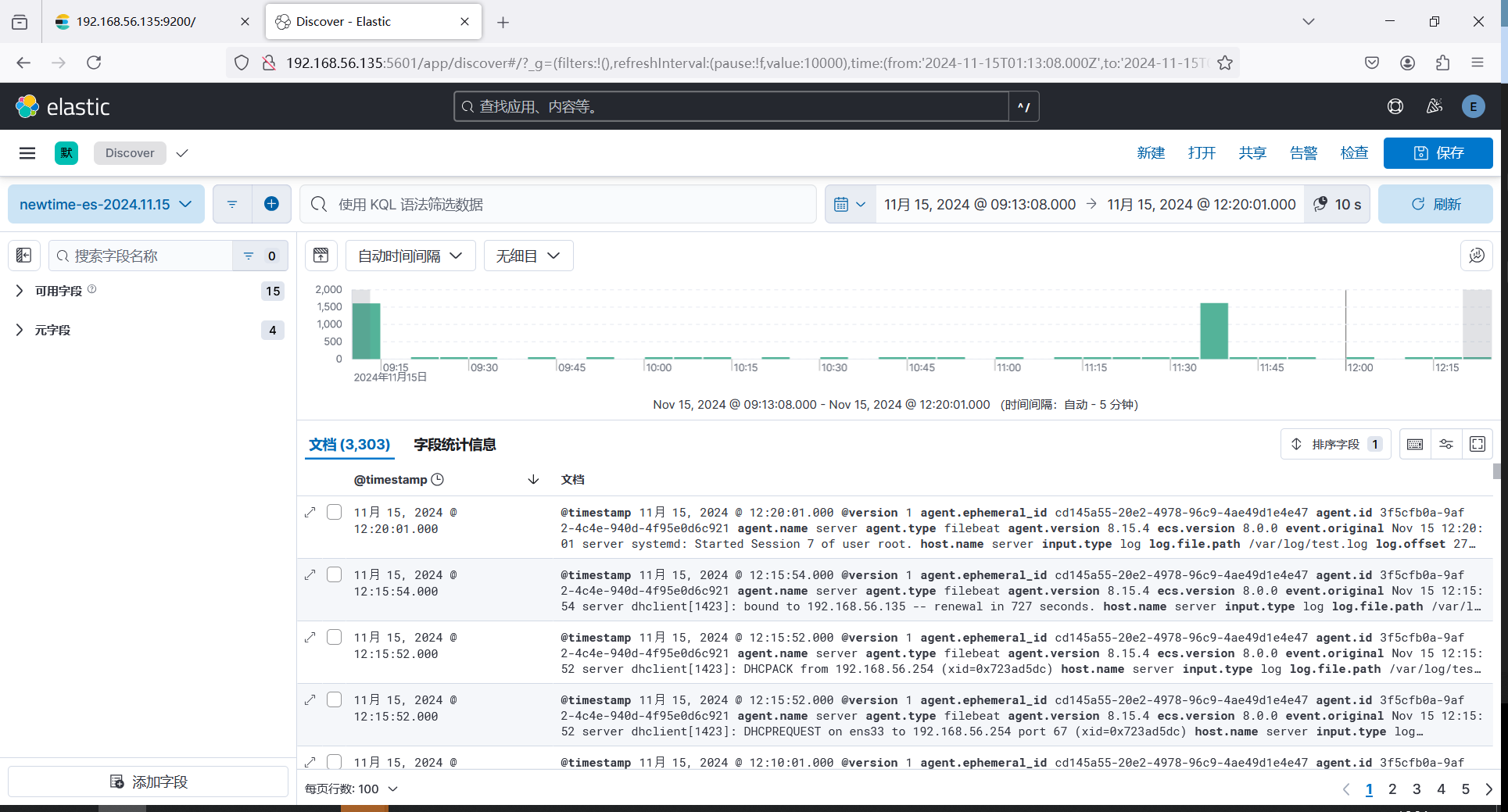
ELK8.15.4搭建开启安全认证
安装 Elastic :Elasticsearch,Kibana,Logstash 另外安装一个收集器filebeat 通过二进制安装包进行安装 创建一个专门放elk目录 mkdir /elk/ mkdir /elk/soft下载 es 、kibana、Logstash、filebeat二进制包 cd /elk/softwget https://art…...
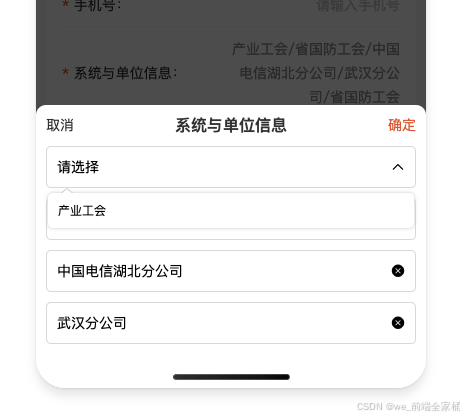
原生微信小程序中封装一个模拟select 下拉框组件
1.首先在components 里面设置组件名称:van-select(随便取名字); 2.新建文件写代码: wxml: <view class"w100 select_all_view"><!-- 标题,可以没有 --><view class…...

商品管理系统引领时尚零售智能化升级 降价商品量锐减30%
根据贝恩咨询公司2024年发布的消费品报告,当前消费品行业正面临增长放缓、全球市场波动及消费者期望变化的巨大压力。为保持市场竞争力,企业需要重新审视其增长战略,重视可持续创新、数字化转型和运营敏捷性。企业必须灵活应对供应链中断和消…...
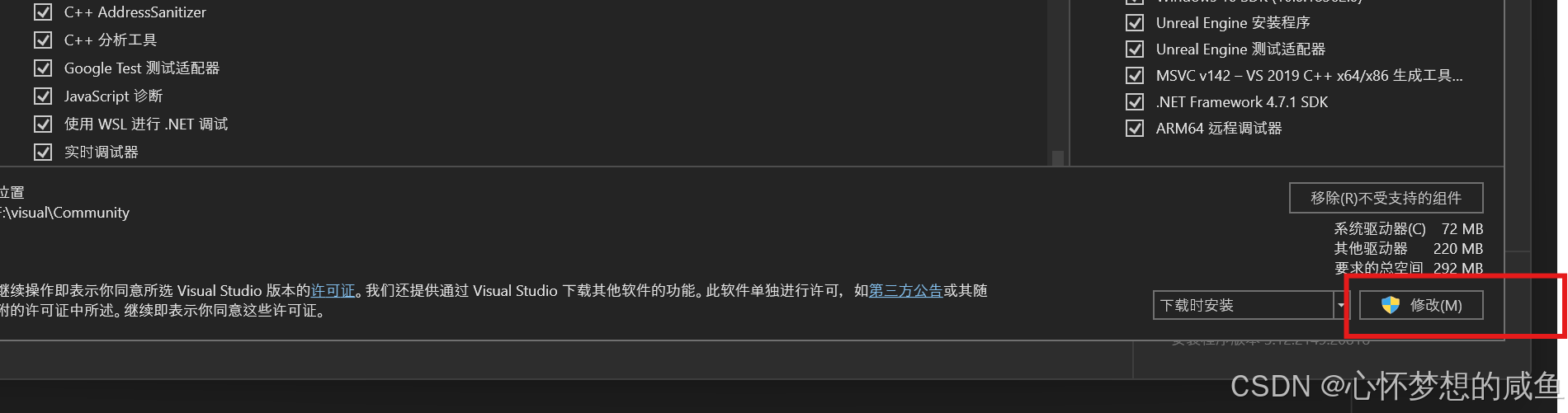
UE5 5.1.1创建C++项目,显示error C4668和error C4067
因为工作要求,没法使用最新 5.5版本的ue5 而是要用ue5.1和5.2版本。 但是我在安装下载了visual studio2022后,使用 ue5.1编辑器 创建C项目,爆出如下错误。 error C4668: ?????__has_feature?????ΪԤ?????꣬???0????…...

spring boot 集成 redis 实现缓存的完整的例子
Cacheable 注解是 Spring Cache 抽象的一部分,用于声明式地管理缓存。Cacheable 注解本身并不直接指定缓存的存储位置,而是依赖于配置的缓存管理器(CacheManager)来决定缓存数据的存储位置。 常见的缓存存储方式: 1、内存缓存&a…...

json-bigint处理前端精度丢失问题
问题描述:前后端调试过程中,有时候会遇到精度丢失的问题,比如后端给过来的id超过16位,就会出现精度丢失的情况,前端拿到的id与后端给过来的不一致。 解决方案: 1、安装 npm i json-bigint 2、在axios中配置…...
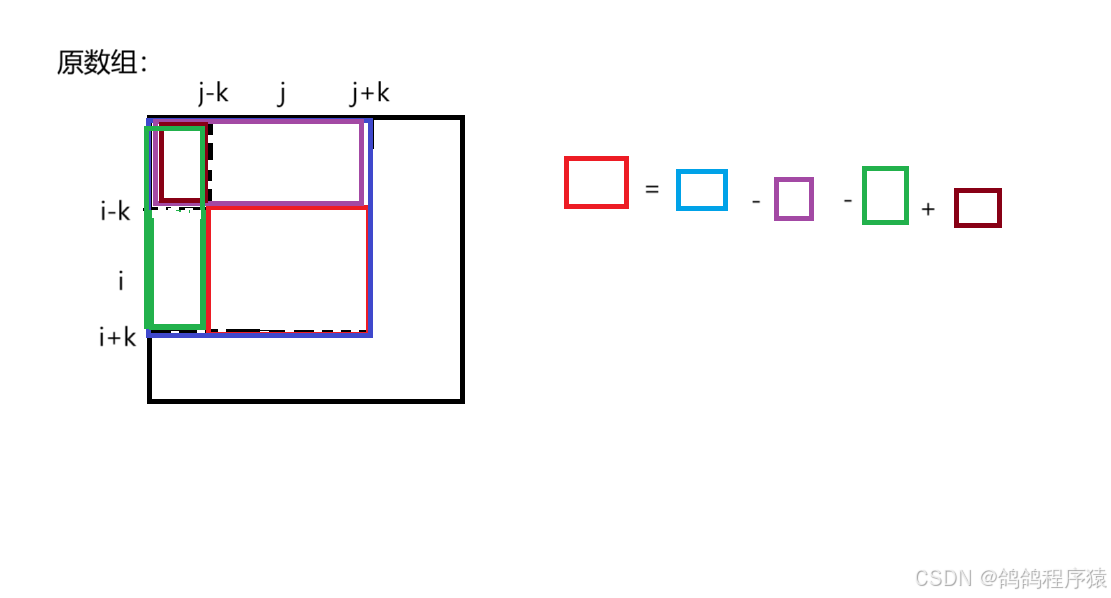
【算法】【优选算法】前缀和(下)
目录 一、560.和为K的⼦数组1.1 前缀和1.2 暴力枚举 二、974.和可被K整除的⼦数组2.1 前缀和2.2 暴力枚举 三、525.连续数组3.1 前缀和3.2 暴力枚举 四、1314.矩阵区域和4.1 前缀和4.2 暴力枚举 一、560.和为K的⼦数组 题目链接:560.和为K的⼦数组 题目描述&#x…...

Node.js 23 发布了!
Node.js 23 现已推出,带来了新功能、性能改进和更好的开发者体验。此次版本提升了兼容性和稳定性,提供了更多工具来构建高效的应用程序。 此外,Node.js 22 将在 10 月 29 日当周被提升为长期支持 (LTS) 版本,进入长期维护阶段&am…...

如何通过低代码逻辑编排实现业务流程自动化?
随着数字化转型的加速,企业对高效、灵活的业务流程自动化需求日益增加。传统开发模式下的定制化解决方案往往周期长、成本高且难以适应快速变化的需求。低代码平台以其直观、简便的操作界面和强大的功能逐渐成为企业实现业务流程自动化的理想选择。本文将探讨低代码…...

thinkphp6模板调用URL方法生成的链接异常
var uul params.url ;console.log(params.url);console.log("{:Url(UserLog/index)}");console.log("{:Url("uul")}"); 生成的链接地址 UserLog/index /jjg/index.php/Home/UserLog/index.html /jjg/index.php/Home/Index/UserLog/index.html…...

Spring Boot汽车资讯:科技驱动的未来
4系统概要设计 4.1概述 本系统采用B/S结构(Browser/Server,浏览器/服务器结构)和基于Web服务两种模式,是一个适用于Internet环境下的模型结构。只要用户能连上Internet,便可以在任何时间、任何地点使用。系统工作原理图如图4-1所示: 4系统概要设计 4.1概…...

嵌入式硬件电子电路设计(五)LDO低压差线性稳压器全面详解
引言: LDO(Low Dropout Regulator,低压差线性稳压器)是一种常用的电源管理组件,用于提供稳定的输出电压,同时允许较小的输入电压与输出电压之间的差值。LDO广泛应用于各种电子设备中,特别是在对…...

qiankun主应用(vue2+element-ui)子应用(vue3+element-plus)不同版本element框架css样式相互影响的问题
背景:qiankun微前端架构实现多应用集成 主应用框架:vue2 & element-ui 子应用框架:vue3 & element-plus >> 问题现象和分析 登录页面是主应用的,在登录之后才能打开子应用的菜单页面,即加载子应用。 首…...

resnet50,clip,Faiss+Flask简易图文搜索服务
一、实现 文件夹目录结构: templates -----upload.html faiss_app.py 前端代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widt…...

使用OkHttp进行HTTPS请求的Kotlin实现
OkHttp简介 OkHttp是一个高效的HTTP客户端,它支持同步和异步请求,自动处理重试和失败,支持HTTPS,并且可以轻松地与Kotlin协程集成。OkHttp的设计目标是提供最简洁的API,同时保持高性能和低延迟。 为什么选择OkHttp …...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...